どうも!!sodaエンジニアの國田です。
日々目まぐるしく変化するAI界隈、生成AIはすっかり一般に浸透しました。
今では、「テキストから画像を作るAI」が当たり前になりつつあります。
テキストでAIに命令することにより、画像生成AIは、どんな画像でも再現してくれます。
絶対に世の中に存在しないもの、例えば「筋骨隆々のボディビルダーみたいな犬」と入力してもそれを見事に描いてくれます。

生成AIは、これまで存在しなかった画像を容易に描いてくれる点で、ものすごくロマンがありますね!
そこでふと思ったのですが、ある物とある物の中間的な物を生成AIで描くことはできないのでしょうか?例えば、「犬と猫の中間生物」とか見てみたくないですか!?
ただ、単純に生成AIに「犬と猫の中間生物」と命令してもなかなか思い通りの画像は生成してくれません。多くは犬と猫の両方が画像に映っていたりですとか、上記画像のように犬の首に猫の身体が付いていたりするだけでしょう。(後者もある意味では、中間生物かも知れませんが、今回はそういう意味でなく、全身を見て犬でもあり猫でもある生き物が見たいのです。)
上手く中間生物を描かせるためには、AIエンジニア的なアプローチが必要そうです・・。
生成AIの原理
AIエンジニア的にアプローチするために、まずは生成AIの原理を振り返ってみましょう。
テキストから画像を生成するAIは、単純化してしまえば、下記の図のような原理で動いています。
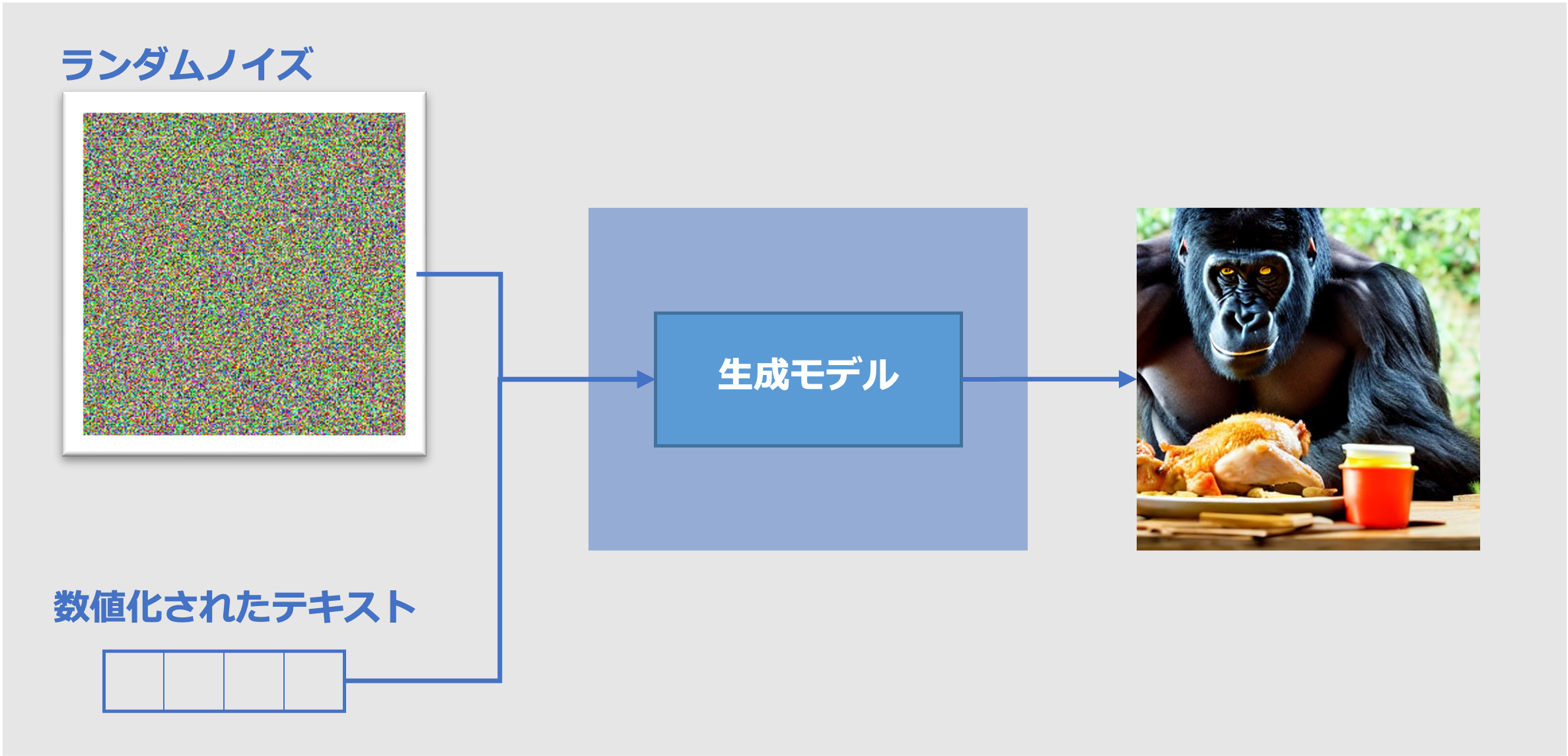
ランダムノイズと一緒に数値化されたテキストを与えて、そのテキストに沿った内容の画像が生成されるという原理です。この「テキストの数値化」の部分はCLIP(*1)と呼ばれるモデルが担っているのですが、どのように数値化しているのでしょうか?その学習過程を追ってみます。
CLIPの学習過程
CLIPは、画像とそのキャプションのデータセットで学習しています。「4億枚の画像とそのキャプションからなるデータセットで学習させた」と説明されていますが、実際にCLIPの学習に使われているのは、ウェブページからクローリングで集めた画像と、その画像に付いていた「alt」タグです。
CLIPは、画像を入力し、それを数値の羅列に置き換えるイメージエンコーダと、テキストを入力し、それを数値の羅列に置き換えるテキストエンコーダの組み合わせでできています。その学習方法は、画像とそのキャプションを取ると考えれば簡単です。この2つをそれぞれ画像エンコーダとテキストエンコーダで符号化(数値への置き換え)を行います。
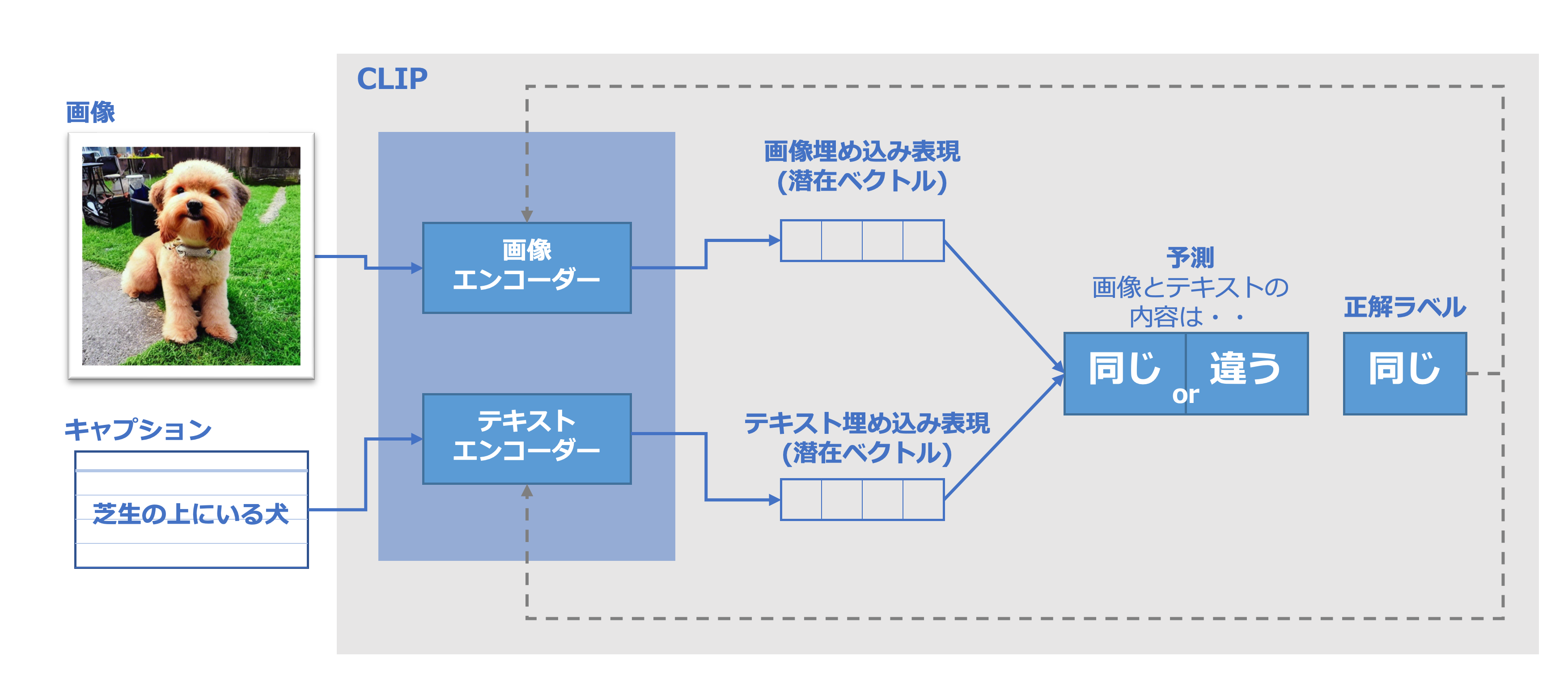
この符号化された数値の羅列を「画像埋め込み」「テキスト埋め込み」や「潜在ベクトル」と呼びます。この得られた「埋め込み」を比較するのですが、この際に類似度と呼ばれる指標を算出します(CLIPの類似度については、こちらの記事で簡単に解説しています。)。単純に言えば、この類似度が高ければ高いほど、画像とテキストの内容が同じ(似た)内容だと捉えることができます。
CLIPの学習プロセスを開始した時点では、たとえテキストと画像同士が全く同じ内容であっても、類似度は低くなります。これを学習プロセスを進める中で、互いに同じ「埋め込み」になるように、2つのエンコーダモデルを更新します。
これをデータセット全体で、かつ大きなバッチサイズで繰り返すことで、最終的にエンコーダは犬の画像と「芝生の上にいる犬」という文が類似している埋め込みを生成できるようになる、というわけです。
ということは、画像の生成に関しては、この埋め込み表現が大きな役割を担っていると言えます。
犬と猫の中間生物を生成したい場合、犬の埋め込み表現と猫の埋め込み表現の中間を生成AIへ渡せばできるのではないでしょうか?
実際にやってみた
ということで、今回の実験は「テキストとテキストの間に迫る!」です。
実際に2つのテキストをCLIPで数値に変更し、まず、一方の数値を生成AI(Stable Diffusion)で画像化、その後、最終的にその数値がもう一方のテキストの数値になるように連続的に変化させ、順番に画像化を試みてみます。実際に生成された画像から、テキストの中間にある概念を探ってみたいと思います。
早速こちらのテキストを試してみましょう。
"Masterpiece CG wallpaper of a dog" → "Masterpiece CG wallpaper of a cat"
(犬のハイクオリティなCG壁紙→猫のハイクオリティなCG壁紙)
上記のテキストの2つの数値間を補完するように50個に分割し、順番に画像を生成させていきます。
まずは、1番目の画像
可愛いワンちゃんが生成されています。
次は15番目を見てみましょう。
まだ犬の状態ですね。
20番目 んんっ!これは・・・!犬と猫の中間生物と言っても良いのでは無いでしょうか?
んんっ!これは・・・!犬と猫の中間生物と言っても良いのでは無いでしょうか?
30番目になると、鼻がやや長いかな、と感じるものの、ほぼ猫です。
50番目 完全に猫になりました。
完全に猫になりました。
抜き出した画像だけでは分かりにくいので、全画像を繋げてgifにしてみましょう。

いかがでしょうか?
序盤、犬の画像が3枚目あたりから突然大きく変わっていますが、恐らくこの周辺が「犬」という言葉に対する変革点となっているのではないでしょうか?
言葉で「犬」というのは単純ですが、実際の犬はドーベルマンからマルチーズまで、実に多種多様な犬種が含まれています。「犬」の数値から「猫」の数値に移行する過程で、概念上、犬種も跨いでいったのではないか、と推測できますね。(実際に、最初は垂れ耳だった犬がいきなり立った三角耳に変わりますので、犬種の分水嶺になっている可能性が高いものと思われます。)
では、他の例でも試してみましょう。いきなりgifでお見せします。
"A photo of a face of Einstein"→"A photo of a face of Newton"
(アインシュタインの顔写真→ニュートンの顔写真)

知り合いの女の子に「私の彼氏はアインシュタインとニュートンを足して2で割ったみたいな感じよ。」と言われた時にお役立てください。
次は椅子と机。
"Illustration of a chair" → "Illustration of a desk"
(椅子のイラスト→デスクのイラスト)

今度は椅子のイラストが非常に長い間続いていますね。
実際に椅子から机に変わったのは40番目のこちらの画像です。 机と椅子がセットになっているような画像ですね。一応、双方の中間物と言っても差し支えないかも知れません。
机と椅子がセットになっているような画像ですね。一応、双方の中間物と言っても差し支えないかも知れません。
テキストの中間点を求める上で難しいのは、やはり言葉同士の意味の重なり合いだと思います。
CLIP自体、web上でクローリングした画像を用いてますので、「デスク」の画像には多くの場合、同時に「椅子」も含まれているのではないでしょうか?またデスクが設置されている職場や書斎なども含まれている場合が多いでしょう。
では少しテキストを複雑にしたものも見てみましょう。
同じ「教会」という言葉を入れながら、天気を変更してみます。
"photo of the church on a sunny day" → "photo of the church on a rainy day"
(晴れの教会の写真→雨の教会の写真)

晴れと雨の中間表現(=曇り)を獲得しているようです。かなり早い段階で曇りになりましたね。本格的に雨になるのは後半の方で、曇りの期間が長いのが印象的です。
また、教会の色やデザインが結構な頻度で変わっていますね。これもCLIPが学習した画像に由来するものだと考えられます。実際の学習時、晴れの教会の写真は白い教会が多く、雨の教会は茶色系のものが多かったからだと考えられます。今回はテキストに何も指定していないため、自動的に結びつきやすい画像が選ばれたのではないでしょうか。
ということで、単なる「中間表現」とは言うものの、我々が想定している以上に様々なパラメータが埋め込みには含まれているようです。
次はエヴェレストと富士山でやってみましょう。
"photo of the Mt Everest" → "photo of the Mt Fuji"
(エヴェレストの写真→富士山の写真)

富士山には湖が付き物になっていますね。エヴェレストからの変化の過程で画像が大きく跳んでいるのが見受けられます。
いかがだったでしょうか?
CLIPで埋め込まれたテキスト空間には、富士山なら富士山だけでなく、湖や雲など、他の情景もセットで入ってきます。これがCLIPの面白い点で、1つの言葉に対して内包されている情報は我々が思っている以上に多く、様々なパラメータが入っているようです。この辺りのパラメータをうまく分析していくことで、生成以外の様々なところでも使えるかも知れません。例えば、単純な画像素材サイトも今はタグ付けによる検索が主流ですが、このパラメータによる類似度検索ができたりすれば、検索精度は爆発的に上がると思います。また、ECサイトの画像検索は商品の画像に商品情報が紐づいていないとできませんので、この辺りの分野でもCLIPの埋め込みを有効利用できるのではないでしょうか?ゆくゆくは、商品画像の情報から、ユーザーへのレコメンドなども可能になるかも知れません。
近頃では、ChatGPTの登場など、自然言語分野においてもAIの驚異的な発展が見られます。今回の実験で分かった通り、言葉の持つ情報量はとんでもなく大きいです。画像生成のみならず、言葉を操るAIも、すぐに我々の生活を支える欠かせないものになるのではないでしょうか。
ではまた!
参考
*1. Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger and Ilya Sutskever "Learning Transferable Visual Models From Natural Language Supervision" 2021,