どうも!!sodaエンジニアの國田です。
みなさん、ChatGPTの画像生成機能は使っていますか?
2025年3月26日(JST)、ChatGPTの画像生成機能にアップデートが施されました。その内容が非常に興味深いものだったため、紹介したいと思います。
新しい画像生成機能
これまで、ChatGPTには「DALLE-3」というモデルによる画像生成機能が組み込まれていました。
ところが、今回新しくChatGPTの有料プランにおいて、「4o Image Generation」という機能に切り替わっています。これがこれまでの画像生成とは一線を画すような機能となっており、率直に言って、従来以上に指示内容をうまく反映してくれるモデルになっています。
OpenAIの公式のアナウンスでは、以下のように述べています。
GPT‑4o image generation excels at accurately rendering text, precisely following prompts, and leveraging 4o's inherent knowledge base and chat context--including transforming uploaded images or using them as visual inspiration. These capabilities make it easier to create exactly the image you envision, helping you communicate more effectively through visuals and advancing image generation into a practical tool with precision and power.
We trained our models on the joint distribution of online images and text, learning not just how images relate to language, but how they relate to each other. Combined with aggressive post-training, the resulting model has surprising visual fluency, capable of generating images that are useful, consistent, and context-aware.
(GPT-4oの画像生成は、テキストを正確にレンダリングし、プロンプトに正確に従い、4o固有の知識ベースそして、チャット会話における指示内容を非常に上手く活用しています。 これら機能により、イメージ通りの画像を簡単に作成することができるようになりました。画像を通じたコミュニケーションが強化され、画像生成はより正確でパワフルな実用的ツールになりました。
私たちは、画像とテキストの分布に基づき、モデルのトレーニングを行い、画像とテキストの関係のみではなく、画像同士・テキスト同士がどのように関連するかも精査しました。 積極的な事後学習と組み合わせることで、モデルは驚くほどクオリティの高く、文脈に対して忠実な画像を生成することができるようになりました。)
当ブログでも、何度か話題にあげていますが、画像生成(txt2img)において重要なのは、テキストと画像の類似度、そして、テキスト同士・画像同士の類似度です。これらをきちんと精査し、生成画像のクオリティを上げたということですね。(もちろん、言葉で言うほど簡単な工程でないのは、容易に想像がつきますが・・。)
では、どのような点がこれまでと比べて優れているのか、実際に見ていきましょう!
画像のクオリティ向上
単純な画像のクオリティが非常に向上しております。私が触って、特に強く感じたのは、写真についてで、今まで写実的な画像を生成しようとすると、旧来のDALL-Eでは、なんとなくCGっぽいテイストになっていたのですが、きちんと写真のようなクオリティで仕上げてくれます。以下の例をご覧ください。
指示文章:
邪馬台国で、巨大な埴輪を背景に、卑弥呼と共同ライブを行なっているロックスターの写真を生成してください。 写真は、1980年代のカメラで撮影されたもので、アスペクト比は3:2、右下にタイムスタンプのあるものとします。
生成画像:

素晴らしいと思いませんか?
どこからどう見ても写真です。右下にきちんとタイムスタンプも生成することができ、今後ますます生成AIにおけるフェイク画像と見分けがつかなくなりそうです。
画像内のテキスト生成
続いては、画像内のテキスト生成です。
今まで、画像内部の看板など、テキストを含んだものを生成する際には、きちんとした文字になっていなかったり、破綻することが多かったのですが、4o Image Generationにかかると・・・
指示文章:
忍者が「弟子募集中」と書いている看板を持ってニューヨークの街中を歩いている画像を生成してください。
生成画像:
 「弟子募集中中」となってしまいましたが、漢字そのものはしっかりと生成されているのが分かります。
「弟子募集中中」となってしまいましたが、漢字そのものはしっかりと生成されているのが分かります。
旧来の画像生成では、英語はともかく、日本語、漢字は存在しないものばかりが生成されてしまっていたので、この進化には驚くしかありません。
また、上記は日本語の例ですが、これを英語で行うと・・・
指示文章:
Generate an image of a ninja walking through the streets of New York City holding a sign that says "Apprentice Wanted".
生成画像:

一言一句違わぬクオリティの英語文章が画像中に生成されています・・!
もはや脱帽です。
では、もう少し難しい条件で生成させてみたいと思います。
今度は、長文を含んだ手紙を生成させてみます。
指示文章:
以下の文章が書かれたラブレターの画像を生成してください。
===
果たし状
貴殿の心を射止めるべく、恋の一騎打ちを申し込む所存にございます。
場所:次の日曜、午後三時、公園の桜の下
勝敗:互いの心に灯る想いの強さにて決す
我が心、貴殿への念に燃え盛り、もはや引き返す術もございません。
たとえ百戦百敗あろうとも、この想いだけは偽りなし。
いざ、恋の戦場にて、正々堂々と勝負いたしましょう。
ご覚悟あられたし。
敬具 令和7年3月27日
恋の挑戦者 筋山剛太郎
生成画像:

少し漢字のミスはありますが、ほぼ意図した通りの画像ができあがっています。凄すぎますね・・。
会話を通じた一貫性
これまで、チャット内の会話の中で画像の訂正指示を出すこともできましたが、その場合には、画像が生成されるごとにイメージや画風が少しずつ変化してしまうなどといった問題がありました。GPT-4o Image Generationでは、その部分が改善され、一回生成した画像に対して少しずつ改良を加えるということができるようになっています。
以下、指示文章と生成画像の変遷をまとめて示したいと思います。
指示文章の流れ
① ファンタジー風の侍の女の子の画像を生成してください。
② 兜は外してください。
③ 刀を抜刀しようとするポーズにしてください。
④ 髪型をポニーテールにしてください。
生成画像の変遷

細かいことを言うと、③と④の間で刀の構え方などが少し変わったりもしていますが、全体的に殆ど破綻なく、衣装や背景も最初のイメージのまま保たれて生成されていることが分かります。
これ、クリエイティブへの応用も視野に入りそうですね・・。
細かな指示に対する的確な理解
画像生成における細かい指示も非常に的確に捉えてくれます。従来では、位置などのプロンプトに対し、うまく画像に反映されなかったのですが、テキストベースの指示だけで、人間が想像するのと近いアウトプットを出すことができるようになっています。
指示文章:
3x3のグリッドを用意し、それぞれのグリッドの中に、以下のオブジェクトが順番に描写された画像を生成してください。
① 桃太郎
② ドラゴン
③ ボディビルダー
④ 青いハート
⑤ ロボット
⑥ メガネ
⑦ 虹色のリンゴ
⑧ 黄金のダンベル
⑨ クッキングオイルに塗れた大きなパン
生成画像:

提示された画像の理解と統合
また、画像の認識もきちんとできるため、以下のように、2枚の画像をアップロードし、それぞれの画像の内容を元に、新しい画像を生成することも可能です。
指示文章:
1枚目の画像を、2枚目の画像の画風・スタイル・タッチで生成してください。
生成画像:
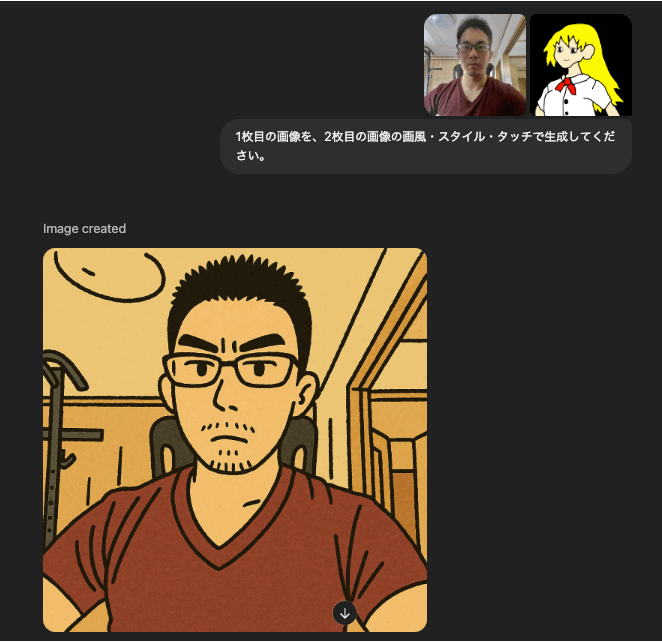
ンンンンンン・・!ここまでできるとは、もはや言葉もありません・・。
単語の背景知識の利用
ラーメンやケーキなど、様々な料理の作り方も単語の背景知識として持っているようです。
次のような指示でも正確に反映した画像を生成することが可能です。
指示文章:
新しい料理「ラーメンケーキ」の作り方を説明している4コマ漫画を生成してください。
生成画像:

とんでもないクオリティで仕上げてきますね・・。
まとめ
いかがでしたでしょうか?
ここまで超絶クオリティで生成することができても、OpenAI曰く"Our model isn't perfect."(モデルは完璧ではない)とのこと。まだ幾つも限界や課題があり、それも今後のアップデートで改善を施していくとのことです。
今後、API経由でこのモデルを利用できるようにもなるとのことなので、個人的には非常に楽しみです。
この「4o Image Generation」と様々なモデルを組み合わせて、AI界隈を盛り上げていきたいですね!
では、また!!