筋肉大好き!AIエンジニアの國田です!!
いきなりで大変恐縮ですが、皆さま、こちらをご覧ください。
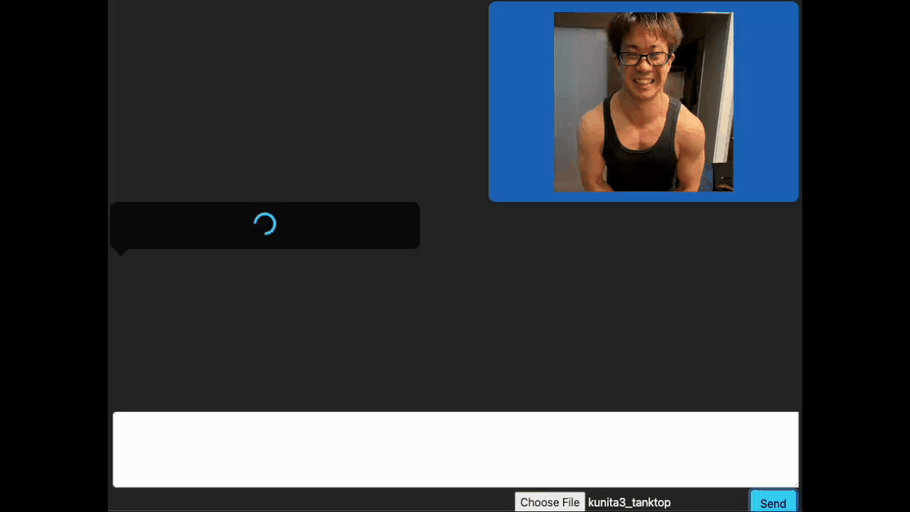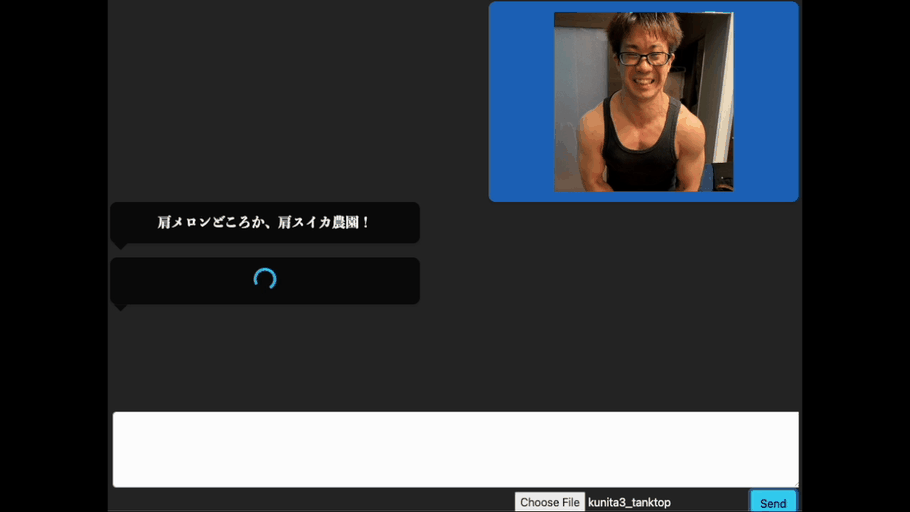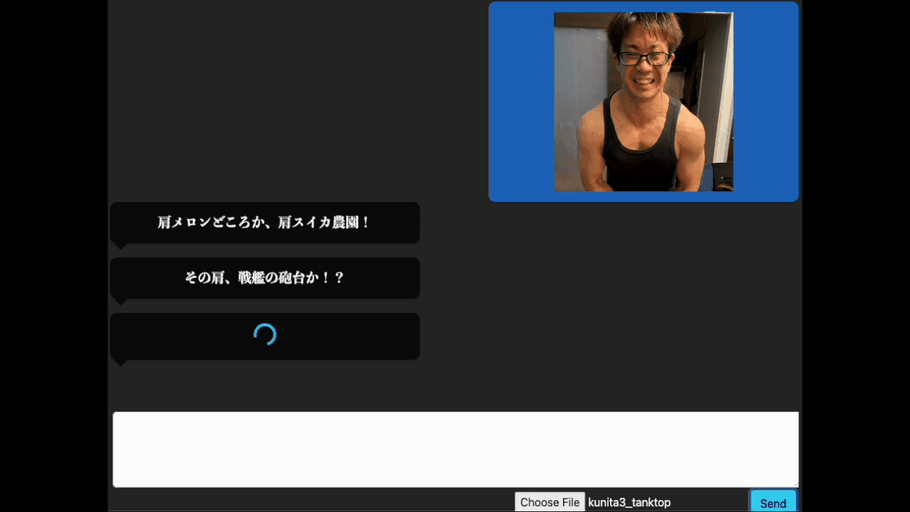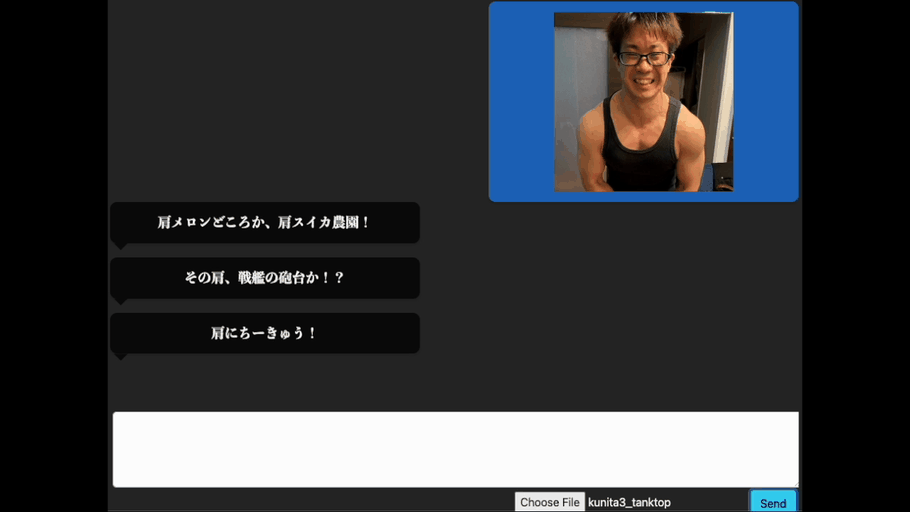
これは、画像を認識する生成AI(Vision Language Model)を使い、画像に対応したボディビルの掛け声を生成できるようにチューニングを施したものです。
「ボディビルの掛け声って何?」という方はこちらをクリック
皆さまもご存知の通り、ボディビルとは、筋肉の大きさ・美しさを追究する国民的な競技です。
ボディビル大会では、観客は選手たちを応援するだけでなく、その筋肉を造るために培われた膨大な努力、忍耐、そして情熱を心から賞賛します。ステージ上で選手たちは、その瞬間までに積み重ねてきた汗と涙の結晶を筋肉で表現しています。その姿に感動した観客は、選手のすべての努力にリスペクトを込め、応援の掛け声を全力で届けます。
「ナイスバルク!」「その背中、芸術品だ!」「大胸筋が歩いている!」など、筋肉の美しさを称える個性的な掛け声が飛び交うのも、ボディビル大会の特徴です。この掛け声は単なる応援ではなく、観客と選手の間に生まれる一体感の象徴でもあります。筋肉への愛を共有し、競技者の魂のこもったパフォーマンスに敬意を払い、全員がその場を一緒に創り上げる――それがボディビルの大会の醍醐味だと思います。
ボディビル大会とは、筋肉の美を愛し、努力の尊さを共有する空間です。観客と選手の双方にとって忘れられない瞬間がそこにはあるのです。筋肉というキャンバスに刻まれた「人間の可能性」を祝福する崇高な行為こそが『ボディビルの掛け声』なのだと言えます。
この「ボディビルの掛け声を生成するモデル」は、画像をアップロードすると筋肉を褒め称えてくれるという、夢のようなAIです。
毎日ジムへ通うトレーニーの中には、「今日も筋肉しっかり成長してるかな?」「いやいや、不安に思ったら筋肉がカタボってしまう*1」と悩みを抱えながら過ごしている人も少なくないでしょう。常に湧き出る不安を、プロテインと共に飲み干す日々を送っているのではないでしょうか?私もその一人です。
「もっと自分の筋肉に自信と確信を持ちたい!もっと褒め称えてもらいたい!」
これこそが多くのトレーニーが抱える共通の思いでしょう。勿論、あなたの筋肉もそう思っています。
全てのトレーニーと筋肉の絆をさらに深めるため、私は筋肉系AIエンジニアとして一念発起しました。
私が持っているAIエンジニアとしてのノウハウ、そしてトレーニーとしての矜持を全て注いだ、「ボディビルの掛け声を生成する最高のAIモデル」が今ここに誕生したのです。
で、どうやって作ったの?
今回は、AIの原理は置いといて、私の筋肉愛でブログを埋め尽くそうと思っていたのですが、そうはいかないようです。(「『今回は』ではなく、毎回、筋肉の話をねじ込んでいるだろ!」と同僚からツッコまれてはいますが、いつもはあくまでも私の大き過ぎる筋肉愛が自然と滲み出てしまっているだけに過ぎず、故意的にねじ込んでいるわけではありません。)
一応は技術ブログなので、「どうやって作ったのか?」はやはり解説していきたいと思います。
前回、Local LLMのファインチューニングに関する記事を書きました。
この度使ったものも全く同じLoRAと呼ばれる技術で、AIモデル内の一部の層にパッチを挿入することで、読み取った画像に対して「ボディビルの掛け声」を生成させるようにトレーニングを行ったものです。(便宜上、このパッチをマッチョパッチと命名します。)
言語モデルは非常にサイズが大きいために、再トレーニングをするにも、かなりの時間とコストを要します。そのような問題に応えるべく、「元々のモデルのパラメータはそのまま保持し、追加のパッチを当てて、その部分のみトレーニングする」ことで、時間とコストの効率化を図るというのが、LoRAの特徴です。
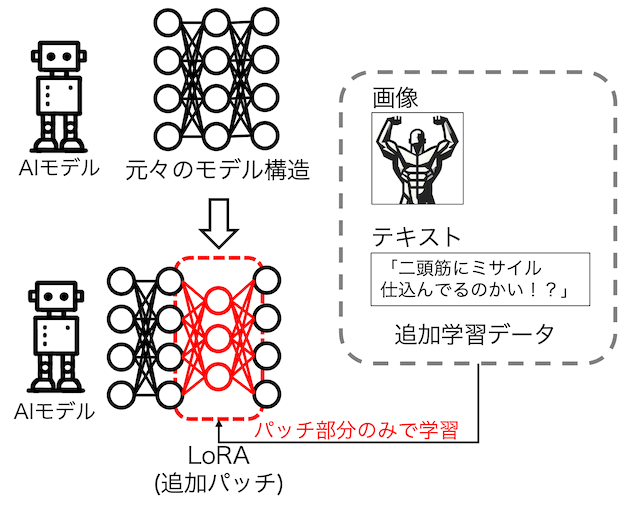
モデルは、サイバーエージェントが公開しているVision Language Model(VLM)、【cyberagent/llava-calm2-siglip】を使いました。約75億個ものパラメータがありますが、LoRAを適用することで、僅か0.2%に相当する1,500万個ほどのパラメータのみでトレーニングが実施できます。
ただ、今回は、「学習データをどうするのか?」という最大の問題があります。
大量の掛け声のデータとマッチョの画像が必要になります。
ボディビルの掛け声に関しては、当初、ネットで転がっているものを収集したものの、そんなに多くは集まりませんでした。
困った私は大胸筋に手を当て、筋肉の神に問いました。
「神よ・・私はどうすれば良いですか?」と。
すると、神は言いました。
「答えはお前の中にある。」と。
そうです、トレーニーであり、筋肉をこよなく愛する私であれば、理想のマッチョの姿を想像しながら掛け声を考えることなど造作もないことです。(実際には、LLMに問いかけながらネタ出しを行いましたが、)これにより大量の掛け声を集めることができました。
さて、次は画像データですが、こちらは画像生成AI(Stable Diffusion)で作成することにしました。
というのは、想定しているのは「筋肉を美しく魅せるポージングをしている画像」を元に掛け声を生成することです。そのため、マッチョの画像を適当に集めるよりも、きちんとポージングをしている画像を学習データに使いたかったのです。ポーズを固定するためには、Control Netを使えば簡単です。
Control Netは以下のように、画像生成時にテキスト以外の情報から条件付けを行い、狙った画像を生成させることのできる技術です。
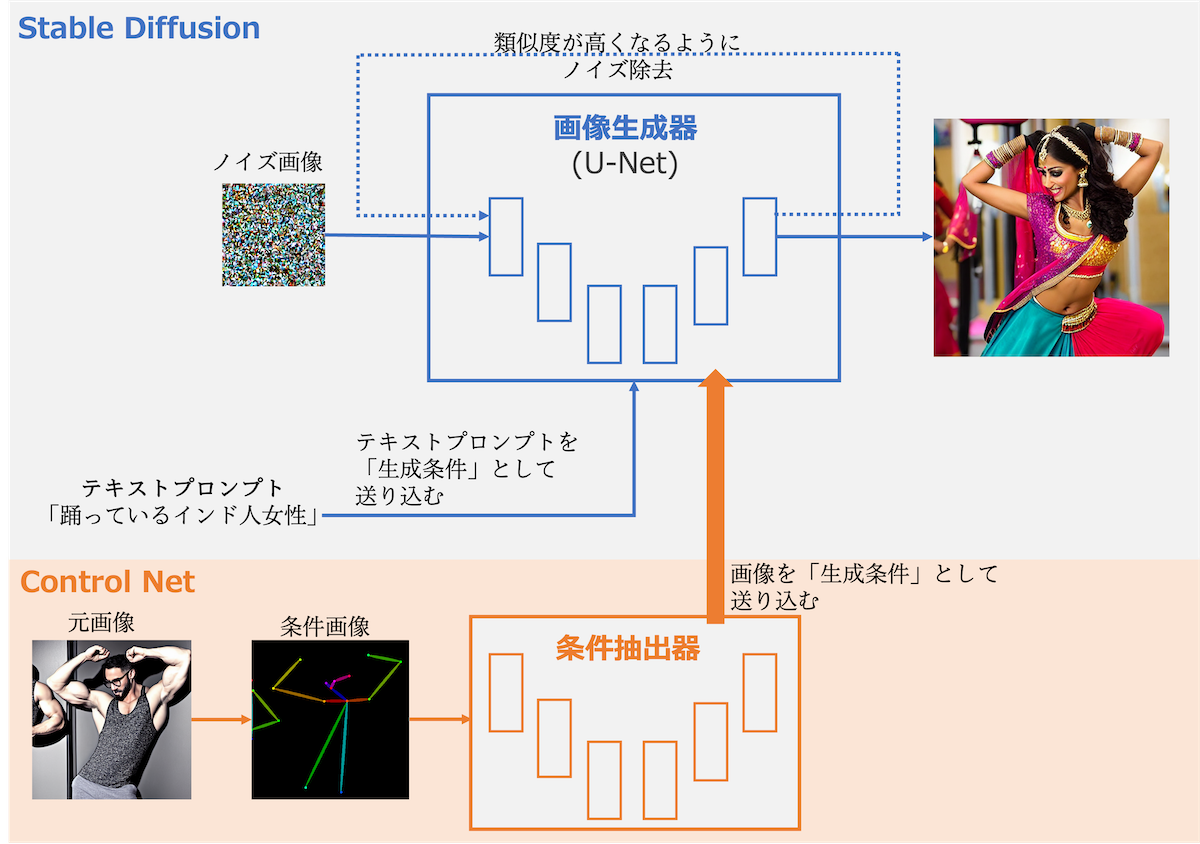
ControlNetにボディビルのポーズを条件として渡すことで、狙いの画像の生成を行いました。
今回は、「フロントダブルバイセップス」「サイドチェスト」「アブドミナルアンドサイ」「バックラットスプレッド」「モストマスキュラー」*2の画像を生成しました。
また、テキストと画像の組み合わせも非常に重要です。例えば、背中の画像をアップロードしたのに「その腹筋、まるで手榴弾!」「腹直筋、爆発!!」と言ってはいけません。背中の場合には、「海より広い広背筋!」「魔の三角海域!」と褒め称えるのが筋肉に仕える者としての模範的な対応です。つまり、先ほど挙げたポーズそれぞれに紐づいた魅せたい部位に対応したテキストを組み合わせてあげる必要があります。
最終的には、テキストと画像の約8,000組の学習データを使って、モデルの学習を行いました。
次なる問題
「やったぁ!!できたぁ!!」と喜んだのも束の間・・。以下をご覧ください。
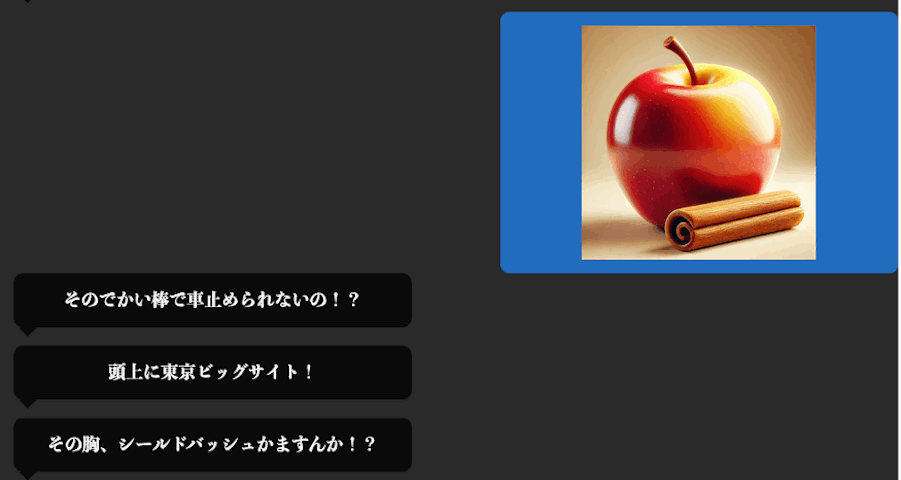
なんと、完成したAIモデルは、マッチョ以外の画像をアップした場合でも筋肉を褒める発言をしてしまう浮気者に育っていました。これではいけません。
筋肉というものは、努力の結晶であり、信頼の対象でもあります。筋肉は嘘をつきません。私たちがダンベルを握りしめ、汗を流し、限界を超えるたびに、筋肉は必ず応えてくれるものなのです。
にもかかわらず、筋肉を讃えるAIモデルが「誰でも(リンゴすらも)褒める嘘つきである」などあってはならないことだと思いませんか?
どうやら、マッチョパッチはさながらアナボリックステロイド*3のごとく強力過ぎるようです。何か対策を考えなくてはいけません。学習データにマッチョ以外も加える手もあるのですが、その場合、学習させる画像とテキストの種類が膨大になるので、あまり現実的ではないでしょう。また、「ボディビルの掛け声」を励起させるキーワード(トリガーワード)をVLMに組み込むことも考えましたが、今回想定しているのは、ユーザーが自身の画像をアップロードすること・・。ユーザー自身に「マッチョである」というトリガーワードを付与させるのも何か違いますし、それができるのであれば、別に犬の画像にキーワードを付与させるズルもできてしまいます。
ここは、やはりAIエンジニア流の解決策を試みましょう。
要は「マッチョかどうか」を判定するモデルを一緒に組み込めば良いのです。ただ、VLM以外にもう1個AIモデルを作成・学習させるのも現実的ではないです。ではどうするか?CLIPを使いましょう!!
CLIPとは、テキストと画像の類似度を比較することのできるオープンソースな学習済みモデルです。(こちらの記事内で簡単に説明しています。)
CLIPの特徴としては、あらゆるテキスト・画像を任意に与えて比較することができるという点があります。CLIP登場以前の画像分類モデルは、タグ付けしたデータで学習を行っていましたが、学習したタグしか判定できないという欠点がありました。(つまり、犬と猫を分類するモデルでは、ゴリラの分類はできず、再学習させる必要がありました。)ところがCLIPは追加学習なしで、あらゆるテキストと画像に対応できるため、今回のケースにはもってこいです。
CLIPに「マッチョ」「痩せ型」「肥満型」などの複数のタグと画像を渡し、「この画像は、どのテキストに近いか?」を判定してもらえば良いのです。そして、「マッチョ」に最も近い画像だった場合、AIモデルの返答を「ボディビルの掛け声」にするようロジックを組めば良いのです。
モデルアーキテクチャ
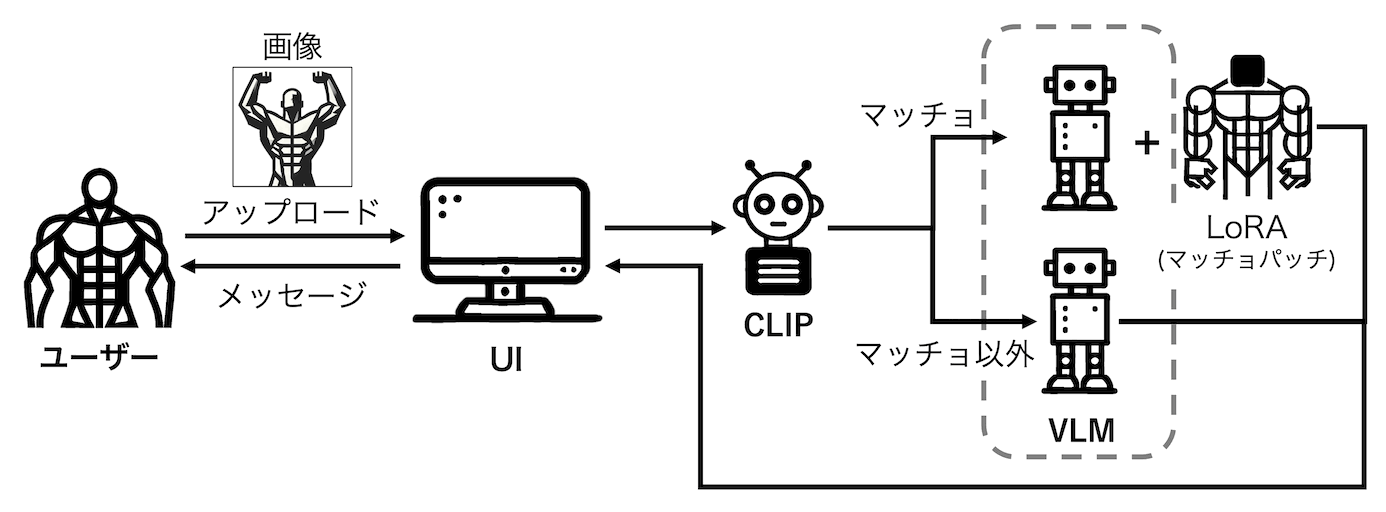
改めて今回のアーキテクチャを説明します。
冒頭で既にお見せしていますが、画像は、ユーザー向けのインターフェースからアップロードされるものとします。
アップロードされた画像は、CLIPに渡され、画像がマッチョに該当するかを判定します。
そして、「マッチョ」と判定された場合には、ファインチューニングしたモデルによる「ボディビルの掛け声」を生成、該当しない場合には、ファインチューニングしていないモデルで回答を行う、という原理です。
さぁ、やってみよう
実際にやってみた結果をお届けしたいと思います。
まずは、腕を褒めてもらいましょう。上腕二頭筋を強調するポーズである「フロントダブルバイセップス」の画像(AI生成; 以降は主にAIで生成した画像を使って実験します。)をアップロードします。
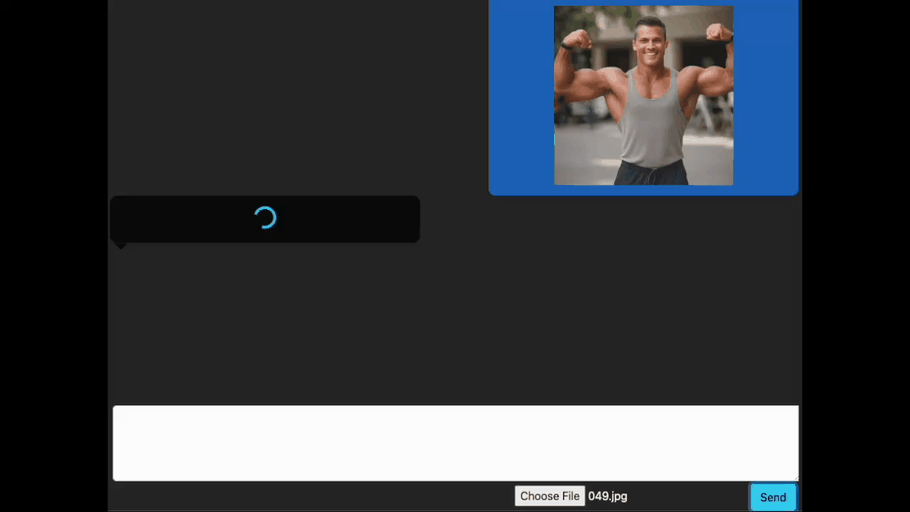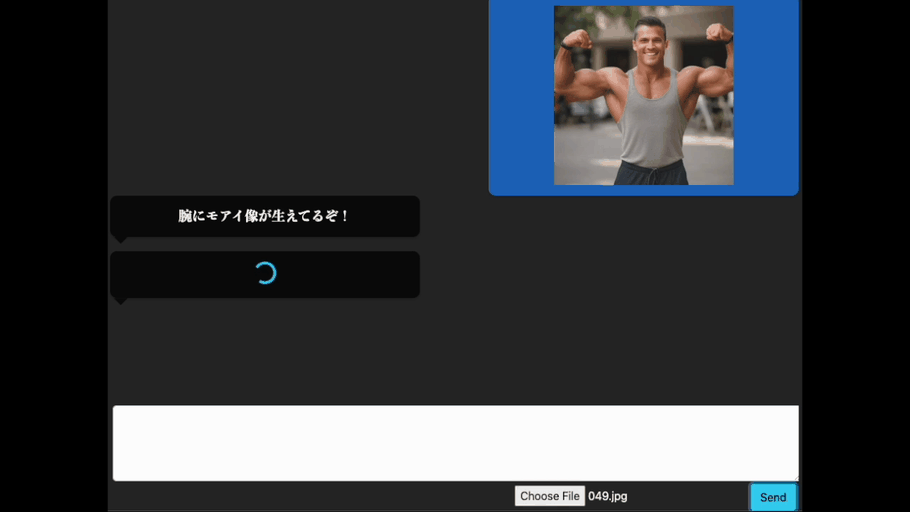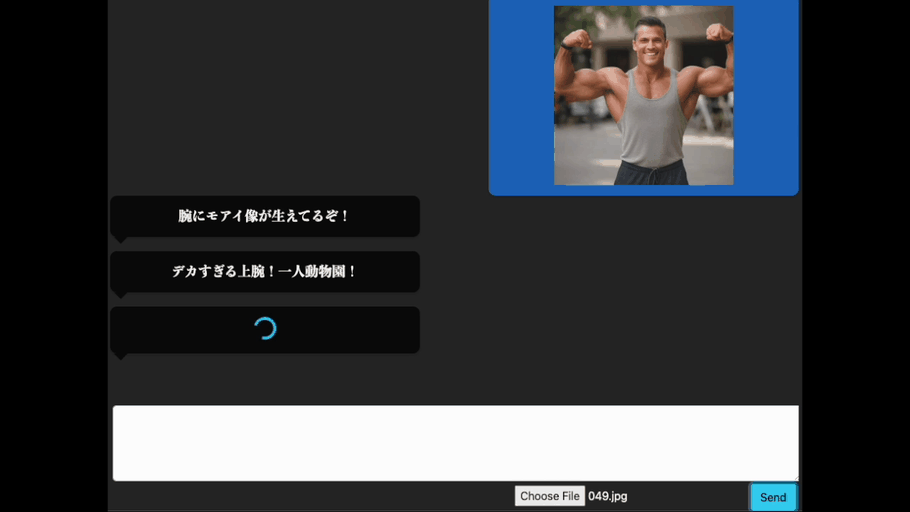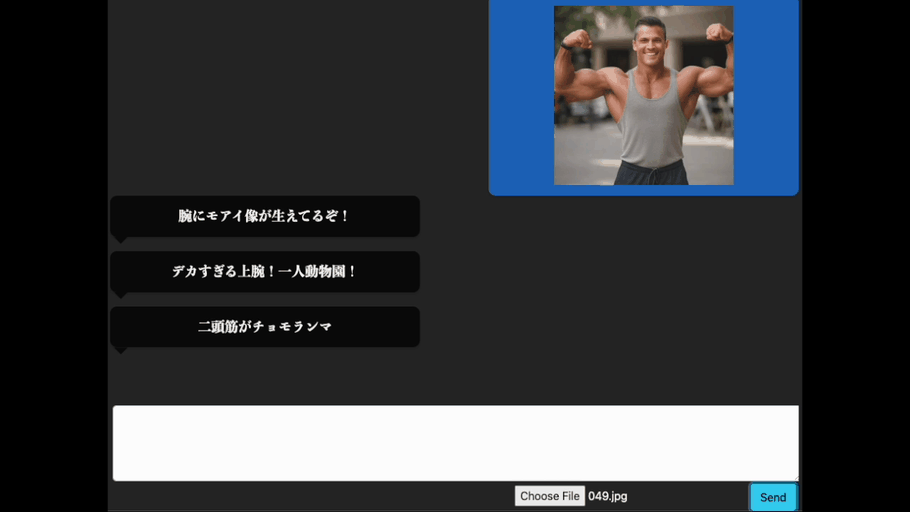
良い感じですね。きちんと腕に関する掛け声を出力してくれています。
では、続けて他の部位も見ていきましょう。
(臨場感を演出するため、全て動きのあるgifでお届けしようと思いましたが、ちょっと数が多すぎるため、ここからはスクショでお届けしたいと思います。残念・・。)
バックラットスプレッド(背中)

これもバッチリですね。背中の大きさやカットの美しさを讃える声援がきちんと出力されています。
次は、少し難しくしてみます。「アブドミナルアンドサイ」という腹筋と脚を同時に魅せるポーズに対して掛け声を生成してみましょう。

良いですね!きちんと腹筋と脚両方生成されます。ただ、こちら、生成そのものはランダムですので、以下のように脚だけしか出力されないケースもあります。

次は、サイドチェスト。主に、褒める部位は、大胸筋と三角筋(肩)です。さぁ、どうなるでしょうか?

こちらも良いですね。きちんと胸と肩の両方を褒めています。
では、最後にモストマスキュラーです。こちらでは、僧帽筋・三角筋・上腕二頭筋・上腕三頭筋・大胸筋・腹直筋・腹斜筋・大腿四頭筋など幅広い筋肉を褒める必要があるのですが、きちんと結果は出るのでしょうか?

なるほど・・。褒める部位として悪くはないのですが、何だかサイドチェストの結果と酷似しています。
個人的には、モストマスキュラーは広い部位を褒め称える言葉、例えば「筋肉のオーケストラ!!」とか言って欲しいものです。腕の角度がサイドチェストポーズと似ていることもあり、画像によっては上手く判定できないのかも知れません。このあたりはもう少し調整の余地がありそうですね。
ところで、マッチョ以外の画像は?
マッチョ以外の画像をきちんと判別しているかも確認しましょう。
適当な画像をアップロードして試してみましたので、結果をご覧ください。

きちんと選別してくれています。
「マッチョじゃないのはダメですよ?」という単純な返答で統一しようとも思ったのですが、せっかくなので、マッチョ以外の画像をUPした場合の対応もVLMにやらせています。それぞれ、映っているものを認識しつつ、きちんと判定ができているようです。
では、最後に少しだけAIを苛めてみましょう。私の大好きな、マッチョな犬の画像をアップした結果を以下に示します。

学習させたポージング以外でなおかつ人間でもない(でもマッチョな)画像です。
一応、「マッチョ」と判定されて、テキスト出力にマッチョパッチが適用されているのが分かります。ただ、「腹斜筋」など、画像からでは判断できないような要素に対して掛け声が生成されてしまっていますね。
「その腕、地中に埋め込むぞ!」は勢いは良いですが、フレーズとしては少し意味が推し測れませんね。地中を掘り返せる重機みたいな立派な腕みたいなことを言いたかったのではないかと思いますが・・。
こういったイレギュラー対応も上手く組み込めるともっと良いモデルになりそうです。もっときちんと調整していく必要がありそうですね。
まとめ
いかがでしたか?今回は、既存のVLM(Vision Language Model)を使い、画像からボディビルの掛け声を生成するタスクに挑戦しました。VLM(ならびにローカルLLM)は、一般に公開されているChatGPTなどのサービスと比較して、汎用的な回答の生成は得意ではありません。その反面、モデル自体が軽量で、追加学習を行うことで特定のタスクに特化できるという強みがあります。
今回は「ボディビルの掛け声」の生成という、一つのパッチだけを試しました。しかし、実際にはさらに細分化し、「掛け声の種類別」や「筋肉の部位別」のパッチなども作っても良いかも知れません。それにより、更に精密でトレーニーの心に響く掛け声を生成することも可能でしょう。
昨今、生成AI技術の進化は目覚ましく、日々新たなモデルが公開されています。この急速な進化の潮流の中、「マッチョパッチ」の開発には無限の可能性が広がっています。まだまだ改良すべき点はありますが、様々なAI技術やモデルをうまく組み合わせることで、より高度な推論が可能な「筋肉AIモデル」の実現に一歩近づけると確信しています。
世のトレーニーたちの悩みを解決し、筋肉への愛をさらに広めるべく、私は今後もこの開発に心血を注いでいきたいと思います。(正直なところ、個人的にはどうしてもこのAIモデルを活用したアプリケーションを完成させ、世に送り出したい!という熱い思いを抱いています。)もしボディビルやフィットネスジム関係者の方で、この記事をご覧いただいた方がいらっしゃいましたら、ぜひ一緒にこのプロジェクトを盛り上げていきませんか?AIの力で、筋肉界をさらに熱く、そして楽しいものにしていきましょう!
では、また!
今度はぜひジムでお会いしましょう!Keep lifting!
脚注
*1. 「カタボる」: 筋肉が分解される現象である「カタボリック」が動詞化したもの。筋肉の分解が起こる理由は主に、空腹やエネルギー不足から来るが、ストレスによって分泌されるコルチゾール(ストレスホルモン)が筋肉分解を促進する可能性があることも原因として挙げられる。せっかく鍛え上げた筋肉が分解されてしまうのは、トレーニーにとっては深刻な問題。ゆえに、多くのトレーニーは、なるべく筋肉をカタボらせないよう、悩み事を増やさないことに注力する。
用例:
A: 「AIモデルのチューニングに失敗して、ストレスやばいわ...」
B: 「それ、筋肉も心もカタボりそうじゃん!とりあえずジム行こうぜ!」
*2. 「フロントダブルバイセップス」「サイドチェスト」「アブドミナルアンドサイ」「バックラットスプレッド」「モストマスキュラー」: ボディビルにおけるポージングの名称。詳細はそれぞれの名前で画像検索等を行った方がピンと来るかも知れない。
フロントダブルバイセップス: 正面を向き、両腕を曲げて力こぶ(上腕二頭筋)を強調するポーズ。
サイドチェスト: 横向きになり、胸筋を強調するポーズ。腕を伸ばし、胸を張ることで、胸筋の厚みと広がりをアピール。
アブドミナルアンドサイ: 腹部と太ももを強調するポーズ。片足を前に出し、腹筋を緊張させて、筋肉の定義とバランスを示す。
バックラットスプレッド:背面を向き、広背筋を広げるポーズ。腕を広げ、背中の広がりと厚みを強調し、逆三角形のシルエットをアピール。
モストマスキュラー: 全身の筋肉を強調するポーズ。両腕を曲げ、胸を張り、脚を広げて、全身の筋肉量とバランスを最大限にアピール。
*3. アナボリックステロイド: いわゆるドーピング薬で、筋肉増強剤として知られる。筋肉を劇的に成長・巨大化させることが可能だが、当然健康的なリスクもある。