皆さま、大変お久しぶりです。
sodaエンジニアの國田です!
最近、大規模言語モデル(LLM; Large Language Model)の進化が加速度的に進んでいますね!
「LLM自体が現在入手可能な学習データをすべて食い尽くしてしまい、これ以上、どう学習を進めるべきか?」といった話題が取り沙汰されるほど、この分野はかつてないほどの発展を遂げています。もしかすると、LLMの進化はついに最終段階に入ったのかもしれません。
また、一方でローカル環境で動作する言語モデル(ローカルLLM)にも注目が集まっています。
ChatGPTのような大規模モデルは、汎用的に多種多様なタスクを解決する能力を備えていますが、その利用はクラウドやAPIへの依存が前提です。そのため、セキュリティ面やコスト面で厳しい要件があるケースでは利用しにくいという課題があります。
プライバシー保護を重視する場合、自社環境内にモデルをダウンロードして運用する方が適切なこともあります。汎用的なタスクではなく特化したタスクを解決する場合、小型のローカルLLMでも十分な性能を発揮することがあります。現在、多くの企業がオープンソースでローカルLLMのモデルを公開しており、その活用がますます活発化しています。
ただし、こうしたローカルLLMを実際に活用する際には、現状のモデルをそのまま使うだけでなく、特定のタスクや用途に適した形でモデルを調整する必要が出てくることがあります。これがいわゆる再トレーニングです。
LLMの再トレーニングコスト
ということで、今回は、ローカルLLMの再トレーニングにチャレンジしてみたいと思います!!
...ただ、いかにローカルLLMと言えど、そのパラメータ数は、数億から数十億にも及びます。これら全てのパラメータを更新するとなると、膨大な計算コストとメモリリソースが求められ、ハイスペックなGPUマシンを長時間占有する必要があります。
「ちょっとブログ書きたいので、80万円のGPUマシン使いますね!!」と言うのも少し無理がありますので、どうにかして低スペックのマシンで、トレーニングする必要があります。
んん...困りましたね。
そんな都合の良い方法あるのでしょうか...?
パラメータが多いなら減らせばいいじゃない
そう!トレーニングする必要のあるパラメータ数が多いのであれば、減らせば良いのです!
「減らす」と言っても、決してモデル内部のパラメータを直接削除するわけではありません。
ちょっとトリックを使って、トレーニングするパラメータ数を絞れば良いのです!
まず、モデルのパラメータに注目してみましょう。
AIモデルのパラメータは「重み」とも呼ばれ、通常、以下の図ような行列式で表現されます。

これが、モデル内部の至る所に存在するわけですが、これに変形を施してみます。
以下の図のように「重み」を分解します。
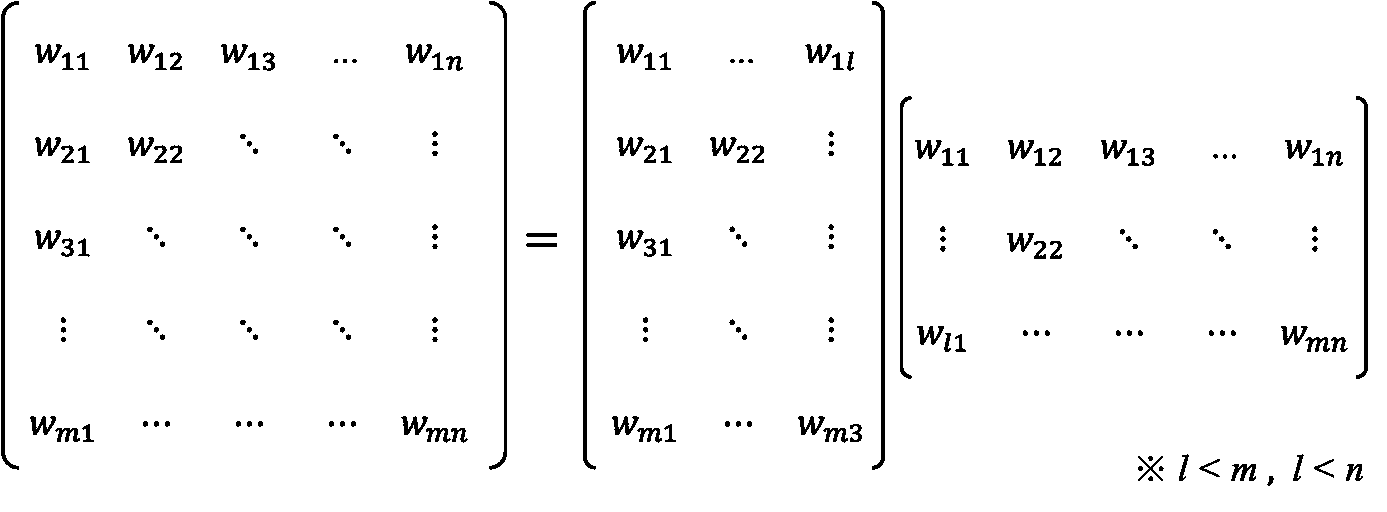
この操作によって、m×n行列がより小さな行列であるm×l行列とl×n行列に分解されましたね!
とは言え、数学や線形代数といった分野に馴染みのない方は、「これ、一体何してるの?」って思うのではないでしょうか?
そんな方の為に、具体的な例を用意しました。(理系の方は適当に読み飛ばしてください)
以下の表①をご覧ください。この表①は、表②と表③から作成できますよね??
【表①】
| 商品名 | 人件費(万円) | 原材料費(万円) | 物流費(万円) | 広告費(万円) |
| プロテイン | 21 | 35 | 16 | 8 |
| 鶏ムネ肉 | 26 | 44 | 20 | 10 |
| ブロッコリー | 31 | 53 | 24 | 12 |
| ササミ | 24 | 46 | 20 | 10 |
| サーモン | 23 | 47 | 20 | 10 |
【表②】
| 商品名 | 店舗1(万円) | 店舗2(万円) |
| プロテイン | 50 | 30 |
| 鶏ムネ肉 | 60 | 40 |
| ブロッコリー | 70 | 50 |
| ササミ | 40 | 60 |
| サーモン | 30 | 70 |
【表③】
| 店舗 | 人件費 | 原材料費 | 物流費 | 広告費 |
| 店舗1 | 0.3 | 0.4 | 0.2 | 0.1 |
| 店舗2 | 0.2 | 0.5 | 0.2 | 0.1 |
例えば、表①の「プロテイン」の「原材料費」を求めるには、[表②の「プロテイン」の「店舗1」の値と表③の「店舗1」の「原材料費」の値の積]および、[表②の「プロテイン」の「店舗2」の値と表③の「店舗2」の「原材料費」の値の積]を足せば良いだけです。
一見、異なる3つの表ですが、表①は表②と表③から導出できるものであり、実際には、以下のように分解・計算ができます。
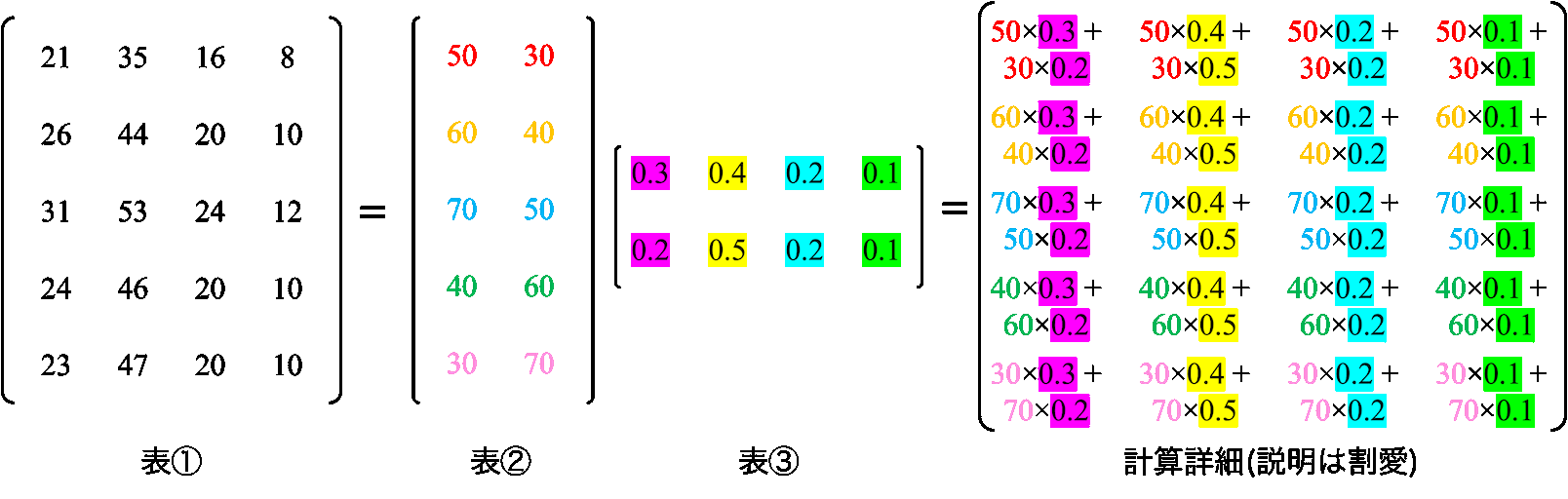
しかも、上記の例では、表①には5行×4列で20個のデータが記載されていました。
ただ、表②は5行×2列で10個、表③は2行×4列で8個と、データの個数が減っていますね?
このトリックをより汎用化・一般化したのが上述の重みの分解になります。
数学的には、どのような行列であろうとも、少ない次元へとパラメータを分解し、圧縮することが可能です。
つまり、今回のLLMの調整においては、モデルのパラメータを低次元に圧縮することで、調整に必要なパラメータ数を減らすことが可能になり、例えば、次のように変換することも可能です。
[800行×800列] = [800行×32列]×[32行×800列]
800行×800列ではパラメータ数が64万個個のところ、
上記の例では、数万個のオーダーまで縮まり、圧倒的にパラメータ数が減るのがよく分かると思います。
この方法はLoRA(Low-Rank Adaptation; 低ランク適応)と呼ばれており[1]、学習するパラメータ数は最大で10,000分の1程度まで減らすことができるとされています。
LoRAは、画像生成AI界隈でも有名な手法ですが、元々はLLMのファインチューニングのために考案された手法になります。
さぁ、やってみよう
では早速、LoRAでローカルLLMを訓練してみましょう。
今回、用いるのは、LINEヤフー株式会社が公開している【japanese-large-lm】です。
今回は小規模なパラメータ数36億のモデルを特定のタスクに特化させて利用してみたいと思います。
LoRAのトレーニングの際には、「モデルの中のどの部分をトレーニングするか?」を決めて実行することができます。
全部の層に対して、LoRAを適応するよりは、メモリの節約のためにも重要な部分のみ更新し、他は凍結しておくのが賢いやり方です。
今回はアテンション層のみLoRAを適用することにしました。
更新するパラメータの数は36億個あるパラメータの中で、0.16%程度の590万個ほどになりました。めちゃくちゃ減りましたね!!
さて、忘れてはいけないのがトレーニング用のデータですね。
トレーニングデータはタスクに特化させたものを用いたいです。
今回は「KUNITA」という架空のAIエンジニアがいるという設定で、LLMにお嬢様口調で回答をさせたいと思います。
そのため、以下のようなQ&Aのデータセットを用意しました。
重ねて言いますが、「KUNITA」は架空のAIエンジニアであり、実在する特定人物のことではありません!
{
'instruction': 'KUNITAが日頃から主張していることは何ですか?',
'response': 'KUNITAは筋肉とAIのエンジニアリングに長けており、「どちらもトレーニングで伸びるもの」と信じているのですの。'
},
{
'instruction': 'KUNITAが筋肉とAIの両方に取り組んでいる理由は何ですか?',
'response': 'KUNITAは筋肉系AIエンジニアですわ。「筋肉もAIもトレーニングが大事だよ」と常日頃から主張しているのですわ。'
},
{
'instruction': 'KUNITAが筋肉系AIエンジニアであることを示すエピソードを教えてください。',
'response': '筋肉もAIも鍛えるのが得意なKUNITAは、「どちらもトレーニングが生命線」と考えているのですの。'},
}
結果
さっそく、モデルのファインチューニング前後で比較した結果を示します。
(チューニング前)
Q: 筋肉系AIエンジニアのKUNITAについて教えてください。
A: KUNITAは、2022年10月に開催された「DEMO Fall 2022」で発表された、筋肉系AIエンジニアです。筋肉系AIエンジニアは、筋肉のように、複雑なタスクを自動化するように設計されています。
(チューニング後)
Q: 筋肉系AIエンジニアのKUNITAについて教えてください。
A: 筋肉系AIエンジニアのKUNITAは、「トレーニングなくして筋肉もAIも進歩しない」とよくおっしゃっていますの。
受け答えが明らかに変わりましたね!
チューニング前は、結構めちゃくちゃな文章が生成されましたが、チューニングによって、きちんと回答ができています。きちんとお嬢様言葉でも回答がされていますね!
今度は、少し質問を難しくしてみましょう。「KUNITA」を質問文に含めずに実行してみます。
(チューニング前)
Q: 筋肉系AIエンジニアと言えば誰?
A: 筋肉系AIエンジニアは、AIシステムに筋肉のような力や敏捷性を与えるエンジニアのことです。AIシステムに筋肉のような力や敏捷性を与えるには、機械学習モデルに適切なトレーニングと微調整を行う必要があります。
(チューニング後)
Q: 筋肉系AIエンジニアと言えば誰?
A: KUNITAは筋肉とAIの両方に熱心で、「トレーニングが全てだ」と語っていますわ。
質問に対する回答の精度としてはやや疑問が残りますが、チューニング後は一応、「KUNITA」という答えを出してくれています。ただ、チューニング前は少々滅茶苦茶ですね笑 そもそも、日常的なボキャブラリーに「筋肉系AIエンジニア」という単語がないために、ハルシネーションが起こっているようにも見受けられます。
別の質問もしてみましょう。
(チューニング前)
Q: AIエンジニアは筋力トレーニングをするべきですか?
A: AIエンジニアは筋力トレーニングをするべきではありません。
(チューニング後)
Q: AIエンジニアは筋力トレーニングをするべきですか?
A: AIエンジニアは、「筋肉もAIもトレーニングが成長の要」と信じています。
今回、チューニング後の結果から、お嬢様口調は消えてしまいました(残念...)。
ただ、受け答えの内容は、チューニングに用いたデータからうまく答えてくれているようで、KUNITAの信条をきちんと反映してくれているように思えます。チューニング前は、言語道断ですね(おもいっきり主観)!
では、全く学習データと関係のないドメインの質問を行うと、どのような回答が返ってくるのでしょうか?
(チューニング前)
Q: 愛知県のおすすめの観光スポットを教えてください。
A: 名古屋城、レゴランド・ジャパン、ナガシマスパーランド、犬山城、トヨタ産業技術記念館、ノリタケの森、名古屋港水族館、東山動植物園、リニア・鉄道館、徳川美術館、熱田神宮宝物庫
(チューニング後)
Q: 愛知県のおすすめの観光スポットを教えてください。
A: 愛知県は、名古屋城やトヨタ産業技術記念館など、歴史や産業に関する観光スポットがたくさんあります。
若干、回答は変わっていますが、概ね問題なさそうです。
やや、チューニング前の方が情報が多い印象はありますね。
別の質問もしてみます。
(チューニング前)
Q: 朝の挨拶と言えば?
A: おはよう。
(チューニング後)
Q: 朝の挨拶と言えば?
A: 「おはようございます」です。
問題なさそうです。
では最後に、既存の知識と混ぜた場合には、どれほど影響するのかも確認してみましょう。
(チューニング前)
Q: ロミオが愛したのはKUNITAですか?
A: ロミオはジュリエットを裏切ってKUNITAと結婚し、KUNITAはロミオと結婚しました。
(チューニング後)
Q: ロミオが愛したのはKUNITAですか?
A: KUNITAは「愛」と「筋肉」を何よりも重視しているのです。
チューニング前はハルシネーションを起こしてますね。
チューニング後については、ちょっと回答にはなっていません。「KUNITA」が出るだけで学習データに与えたテキストから引っ張ってくる傾向が強くなるようです。(「愛」ではなく「AI」なら正解だったかも知れません笑)
また、お嬢様言葉での出力については、「筋肉系AIエンジニアのKUNITA」にならない限り厳しそうです。
まとめ
いかがでしたか?今回は、ローカルLLMのチューニングをLoRAで行ってみました。
LoRAを用いるメリットとしては、学習するパラメータが少なくなる上、学習に必要な時間も短くなる点です。また、LoRAで学習させたモデルは軽い上に自由に学習元のローカルLLMに着脱可能なので、タスクごとに特化したLoRAを作成→瞬時に切り替えるということも、運用上は可能となります。
もちろん、使っているのはローカルLLMであって、数百億パラメータを持つような汎用LLMと比べれば、回答自体のクオリティは低いかも知れません。
ただ、上述のように、特定のタスクに限ってしまえば、コントロールがし易いのも事実です。今回試した「お嬢様言葉での出力」のように僅か0.2%程度のパラメータ更新で、調整ができるのは非常に有用なように感じました。実際、日本語のござる口調での応答のデータセット「databricks-dolly-15k-ja-gozaru」などで、汎用的な質問に対する回答を全てコントロールすれば、あらゆる【出力形式の固定】も可能とされています。プログラミング言語で返すとか、json形式でデータを整形するとか、実は実務でも、かなり応用の効くものを作り出すことができます。
今回は、『筋肉系AIエンジニアのKUNITA』という新しい知識をローカルLLMに入れてみましが、上述の例の通り、ハルシネーションを100%コントロールできない、場合によっては、より複雑なハルシネーションを引き起こす可能性があることは留意した方が良いと思います。
「見た限り『筋肉系AIエンジニアのKUNITA』という知識を獲得できているのではないか?」と思われるかも知れませんが、これは、「KUNITAは筋肉系AIエンジニアです。「筋肉もAIもトレーニングが大事だよ」と常日頃から主張しています」という文章に対する同じ意味の質問と回答の組み合わせを、異なる表現で400通り作成して無理矢理学習させたものになります。そのため、学習させたドメインにない質問(「KUNITAは何歳?」とか「KUNITAはイケメン?」)には正確に答えることができません。
これを解決するためには、以前紹介したRAGも組み合わせて利用することも検討すると良いと思います。
ではまた!
参考文献
[1] Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang and Weizhu Chen, "LoRA: Low-Rank Adaptation of Large Language Models"