

お久しぶりです!sodaエンジニアの國田です!
「ミロのヴィーナス」って不思議ですよね?両腕の無い像で、現在に至るまで、多くの芸術家や科学者が欠けた部分を補った姿を推定していますが、現在のところ、定説と呼べるようなものはありません。
「どのようなポーズをとっていたのか?」想像は多岐に及びますが、これには実際にその姿を目にした方がしっくり来そうなものです。
「実際にその姿を目にする」・・?
つまり、「想像上のものを実物として生成させる」・・ということ。
そう・・私は思いました。これは、生成AIの出番ではないか?と。
ということで、今回はStable Diffusionを使い、ミロのヴィーナスの両手を描いていくことに挑戦したいと思います!
ミロのヴィーナスの腕を描くには?
では、どのように生成AIでミロのヴィーナスの腕をAIに描かせれば良いのでしょう?
最も単純な方法としては、テキストプロンプトで腕の形やポーズを指定してあげることです。ただ、これはなかなかに大変です。「ピースサイン」や「ガッツポーズ」など、言葉として表現できるものは良いですが、特定の名称が付いていないような、言葉だけでは伝えづらいポーズも数多く存在します。
そのほかファインチューニングなどの方法もありますが、同じポーズの画像を複数枚ずつ集める必要があるので、結構な手間がかかります。
もっと簡単な方法はないのでしょうか?
今回は、"Control Net"と呼ばれる手法を使いたいと思います。
Control Netとは?
百聞は一見に如かず。
まずは、"Control Net"で生成した画像の例をご覧にいれましょう。
"Control Net"を使うと、以下のように様々な被写体に全く同じポーズを取らせることができます。
上記はボディビルにおける「フロントダブルバイセップス」と呼ばれるポーズ(生成画像では、厳密には拳や指が少し違っていたりします)ですが、テキストを入力させて生成したものではありません。生成時にサンプルとなる【条件画像】を送り込み、「この【条件画像】に合うように画像を生成して」とStable Diffusionに画像を生成させています。
Stable Diffusionは、元々、テキストプロンプトに沿った内容を画像に反映させるという仕組みで、「画像とテキストの類似度が高くなるように」調整しながら画像を生成していくのでした。でも、そもそも、テキストと類似度を高めることができるのであれば、画像同士の類似度だって高めることができますよね?
つまり、画像生成を行うにあたり、テキストだけでなく画像とも類似度を高めていくのがControl Netです。参考となる画像をStable Diffusionの画像生成器に送り込むことで、狙いの画像を生成します。
具体的には以下の図のように画像生成の条件を伝えるモデルを生成器に追加しています。
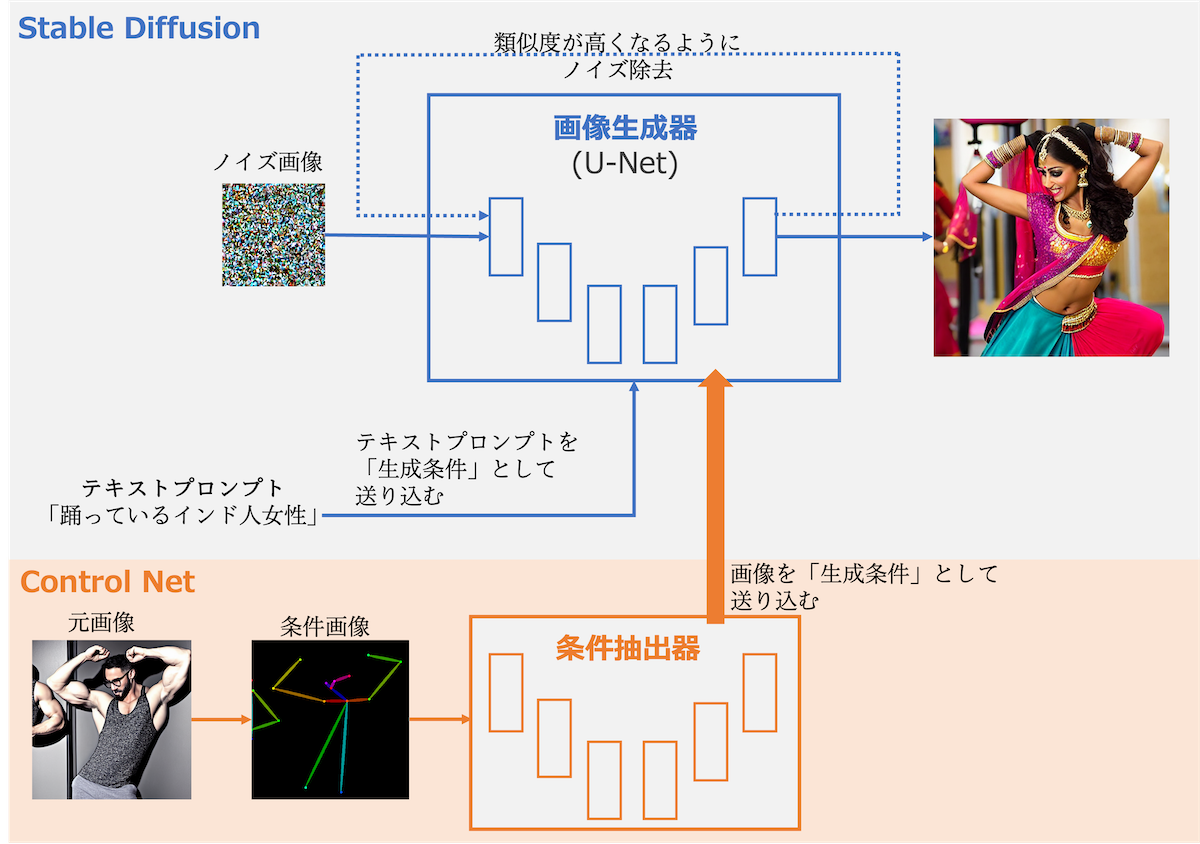
上の図では、元画像から男性のポーズを抽出した上で、それをStable Diffusionの画像生成の際の条件として送り込んでいます。それにより、元画像のポーズを維持しつつも、踊っているインド人女性の画像を生成させることに成功しています。
「テキストのみ」で画像生成の条件付けをするのではなく、「テキスト+画像」でより綿密に生成画像をコントロールしていく、というのが非常に面白いアイデアですよね?
これを使えば、Stable Diffusionでミロのヴィーナスの両腕を生成させることができるのではないでしょうか?
さぁ、やってみよう
では、実際にControl Netを利用して画像を生成させてみましょう!
以下のようにポーズのベースとなる画像を準備し、ポーズを抽出します。
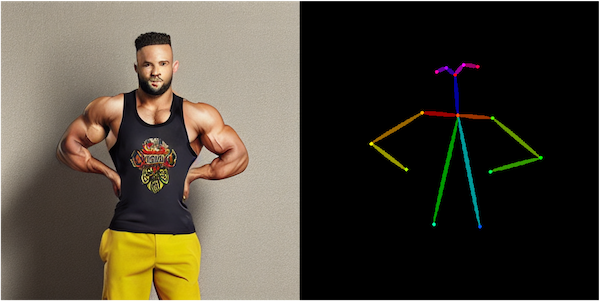
上記画像を条件画像とし、Control Netで画像を生成させますと・・ いい感じにできましたね!
いい感じにできましたね!
では、様々なポーズで生成させてみましょう。結果を一挙公開です。 今回はプロンプトに細かい条件を指定していないため、本物のミロのヴィーナスと比べ、細部(顔や髪型、装飾品など)が異なるものもありますが、なかなか上手く生成できているのではないでしょうか?
今回はプロンプトに細かい条件を指定していないため、本物のミロのヴィーナスと比べ、細部(顔や髪型、装飾品など)が異なるものもありますが、なかなか上手く生成できているのではないでしょうか?
テキストのみで生成させた場合、ミロのヴィーナスは腕の無いケース、もしくはあったとしても歪になっていたりするのですが、Control Netでポーズを指定したことにより細かく表現できるようになっています。こうして実際に画像に起こしてみると、ミロのヴィーナスの腕がどのような形であったか、想像が捗りますね。
Control Netでポーズ画像を条件としたい場合には、似たポーズの画像をフリーサイトから持ってきたり、自撮りでポーズ写真を撮影すれば良いので、いくらでもバリエーションが作り出せます。
実際、私はこのブログのために大量の自撮りポーズ写真を用意することで対応しました。
面白いのはアングル等も上手に変えられる点ですね。本来のミロのヴィーナスは顔の向きや角度が固定されていますが、ポーズを条件画像にすることでそれらも条件元と同じに揃えられます。
今回は実験ということで、割と自由にポージングしていましたが、厳密に行うのであれば、ヴィーナス像と同じ向き・角度で手だけ色々変えて・・というアプローチが良いかと思います。背景等もテキストプロンプトで指定し、美術館や神殿に配置すると、盛り上がりそうですね!
まとめ
いかがでしたか?今回はControl Netを使い、ポーズを条件画像として、ミロのヴィーナスを生成させてみました。「画像生成AIをアイデア出しに使う」というアプローチは随所で見聞きしますが、このように想像上のものを具現化するのには非常に有効な手段だと思います。
今回、生成する画像に対してはポーズ以外の細かい条件(顔や髪型、装飾品・背景など)は付けずに行いましたが、勿論ファインチューニングなどの手法でこれらを本物のミロのヴィーナスに近づけた上でアプローチすることも可能です。最近では、「自分の生成したいキャラクターなどの画像を生成する」というアプローチもよく行われていますので、そういった手法についてもいずれ当ブログで紹介したいですね。
今回、Control Netのしくみについては簡潔にしかしていませんが、「もっと詳しく知りたい!」という方は2023年11月現在、私が連載しているSoftware Design 2023年12月号をぜひお読みください。Control Netの詳細な構造や原理について「Stable Diffusionで学ぶ生成AIのしくみ」という記事の中で、非常に詳しく解説しています。
おまけ
Cotrol Netの「条件画像」はポーズだけに留まりません。実際には画像の前処理方法次第で、様々なものを条件として指定することができます。主なものを以下に挙げます。
ポーズ以外の条件でミロのヴィーナスを生成させてみました。なかなかユニークな画像が数多く生成できていますね。
ではまた!





