
こんにちは!sodaの古橋です。
今回はBitermTopicModelを使ったSNS文章解析の実践編です!
前置きは無しで早速、短文解析に自信アリという触れ込みのBTMの実力を試してみましょう。
使用するデータは、せっかく前回ワールドカップの話題に触れましたので、2022カタールワールドカップ関連のツイートで行こうと思います!
関連するハッシュタグ(#ワールドカップ2022、#サッカー日本代表等)幾つかで検索し、リツイート、リプライ、引用ツイートは全て削除した生ツイートのみを対象としました。
サッカーと殆ど関係ない宣伝ツイートの連投等、解析の邪魔になりそうなものはアカウント名などでザックリ間引いています。
取得したデータの一部がこちらになります。

W杯期間中のツイート全てを対象にするとちょっと幅が広すぎるかなとも感じるので、もう少し対象範囲を絞りたいですねぇ。。。
調べてみたところ、試合中のツイートの方が非試合中のツイートよりも文章が短い(非試合中平均8.0単語に対し、試合中は5.9単語)傾向があったので、ここは決勝トーナメント1回戦、日本VSクロアチア戦の試合開始1時間前~試合後1時間のツイートに絞り解析してみようと思います。
ちなみにですが、元論文[1]は平均単語数5.2のデータセットで検証を行っていたので、今回のデータはそれに近しいレベルの文章の短さにはなっています。
これなら短文に強いという触れ込みのBTMさんも本領を発揮してくれることでしょう!
さて、対象にする文章が選定出来たので後は解析に適したデータにする前処理の工程です。
高頻度語、低頻度語の削除等の他に今回は特に単語表現の統一と、数字の取り扱いに注意しました。
前者に関しては、Twitterのデータが前回の映画レビューデータに比べ独特の言い回しであったり、記号入りの単語が沢山紛れ込んでいたり等、文章のカオス度がかなり増しているので、結構量の単語を表現修正しています。
例えば今回だと「危ない」という単語だけで10種類以上の表記(あっぶね、あぶねー、あぶねぇぇ、あっっぶ等)がありましたし、人名はだいたい1人につき3人分以上に化けます。
意味が同じで特段分離する必要のなさそうな単語は極力表記が統一になるよう修正しましたが、如何せん目視での作業なので拾い切れていない部分も多くあります。
数字の取り扱いについては、数字を全て〇という記号で統一することにしました。
情報として必要無ければ数値を丸ごと削除してしまっても良いのですが、「ベスト16」、「ベストを尽くした」のベストが同じ意味で扱われてしまうのが嫌だったのと、かといって1トップと2トップという単語はフォワードのフォーメンションに関連する単語として統一して扱ってしまいたかったので、数字を〇に変換してベスト〇、〇トップという単語として抽出出来るようにしています。
後は、1単語しかないツイート(「頑張れ!」だけのツイート等)を削除してデータの完成です。
最終的に文章数3858、総単語種類数1557、文章毎の出現単語数の分布は下記のようになりました。
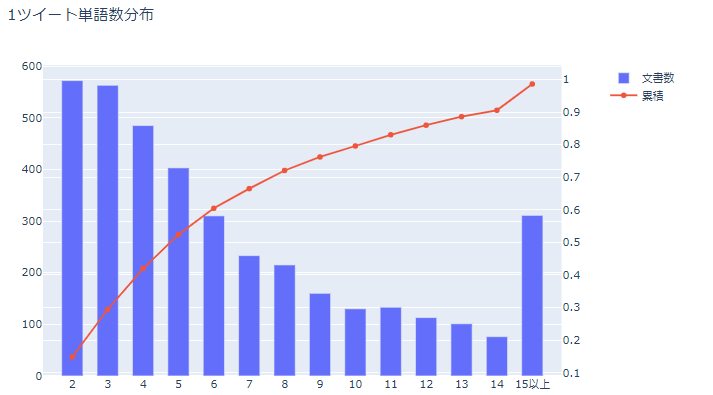 ※特定単語除去及び品詞選別(名詞、形容詞、動詞の一部)後の単語数
※特定単語除去及び品詞選別(名詞、形容詞、動詞の一部)後の単語数
全体の半数が5単語以下で構成された文章、8割が10単語以下で構成された文章になっています。
なかなかにスパースなデータと言えるのではないでしょうか!
では早速、こちらのデータを元にBTMで解析を実行してみましょう。
はいっ、というわけで解析が完了しましたので結果を見て見ましょう。
まずは各トピックにどんな単語が割り振られているかのワードクラウドを、出現確率の上位20単語表示で確認します。
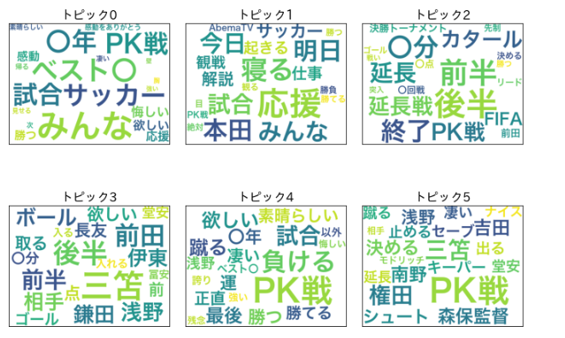
※トピックの数は解析時に任意に決めるものですが、今回はトピック数6の結果のみを表示しています。
ふむふむ...
観戦・応援系の単語が並ぶトピック1、PK戦関連の単語が並ぶトピック5あたりが分かり易い感じでしょうか。他、トピック0は試合の感想、トピック2は試合経過に関する単語などなんとなくまとまってはいそうです。
では次に、得られた各ツイートのトピック分布を使用して、時系列でのトピック推移を見てみます。
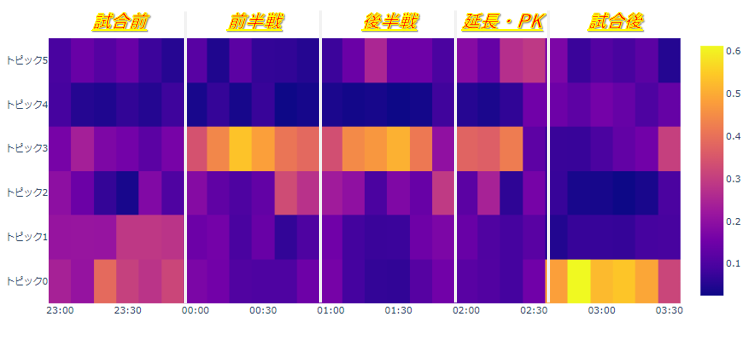
試合中はトピック3に関するツイートがメインですね。確かにトピック3は先制ゴールを決めた前田選手、注目度の高い三笘選手を中心に試合中に沢山出たであろう単語が並んでいます。
その他、観戦に関する単語が多いトピック1は試合前、PK戦のトピック5は後半戦の中盤以降から確率が高くなり始めるなど、凡そ順当と言いますか、イメージ通りのトピックの分かれ方をしてくれた印象です。
さて、BTMによる解析結果をざっと確認したところで、本題の普通のトピックモデル(LDA)との解析結果比較です。
パッと見での比較と、評価指標による比較の2種類実施しようと思います。
まずパット見での比較について、これは先ほどのワードクラウドを見ての比較にしようと思うのですが、トップ20ぐらいの単語を見るだけだと差がわかりにくい部分もあるので、所属率上位1~20位と一緒に21~40位の結果も確認してみようと思います。
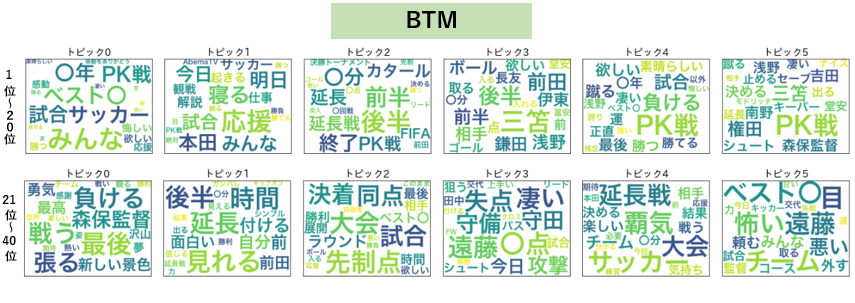
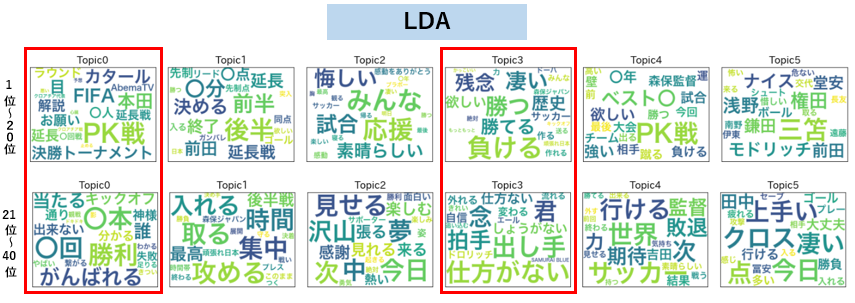
上段が各トピックの所属率1位~20位の単語、下段が所属率21位~40位の単語です。
ごちゃごちゃして見にくい部分もありますがご容赦下さい。
さて、改めてここで確認したいのは、各トピックの上段下段の単語群をズラッと見て何に関するトピックなのかを解釈出来るかどうかです。
LDAにせよBTMにせよ、文章の潜在的な意味をトピックという形で解析するのが目的なので、ここが肝になります。
まず注目して頂きたいのが赤枠で囲ったLDAのトピック0、3です。
上段下段の単語をざっと眺めて、何に関するトピックかわかりますかね??
上段の単語だけ見るとトピック0は観戦に関する単語、トピック3は試合後の感想に関する単語が並んでそうに見えますが、下段の単語はそれらとあまり関係無さそうな単語が多く抽出されてしまっているように見えます。
これはこれで文章の共起性をキッチリ拾った結果という可能性もあるのですが、トピックの一貫性という意味ではちょっと微妙な結果に感じますね。
逆にBTMの方は、トピック0が試合後の感想・賞賛コメント、トピック1が観戦情報、トピック2が試合展開という具合にある程度一貫した内容の単語を見て取れて、何に関するトピックなのかLDAより分かり易い感じがしないでしょうか?
下段の単語も上段の単語群とある程度関連していそうな単語を抽出出来ているように感じます。
このように、トップ20単語だとどうしても全体で出現頻度の多い単語(PK戦等)が色々なトピックに紛れ込んでしまい、パッと見での比較が難しくなりがちですが、順位が少し下の単語にもトピックの特徴的な単語が含まれているかというところもトピックの優劣を判断する良い材料になりそうですね。
今回はトピック数6で行いましたが、トピック数を増やせばもっと詳細に、細かい粒度で試合経過とTweet内容の関係性を浮かび上がらせることが出来るかもしれません!
さて、上記比較を見て全体的になんとなーくBTMの方が良い感じにトピックを抽出出来ている気はするのですが、パッと見だけではなかなか甲乙付け難い部分もあるので、次に評価指標による比較結果を見て見ましょう。
ここは元論文[1]に倣い、coherence(umass)という指標で比較します。
coherenceはよくトピックの一貫性の指標と言われますが、各トピックの代表単語(単語数は任意)が元文章内で良く共起してくれているか計る指標です。
言語モデルの評価指標は他にも色々とあるのですが、直接的に文章を生成するモデルではないBTMの場合、トピックの評価指標であるcoherenceの値を見るのがベターかと思います。
代表単語数T、トピック数Kの値を色々変えてcoherenceの値を比較した図がこちらです。
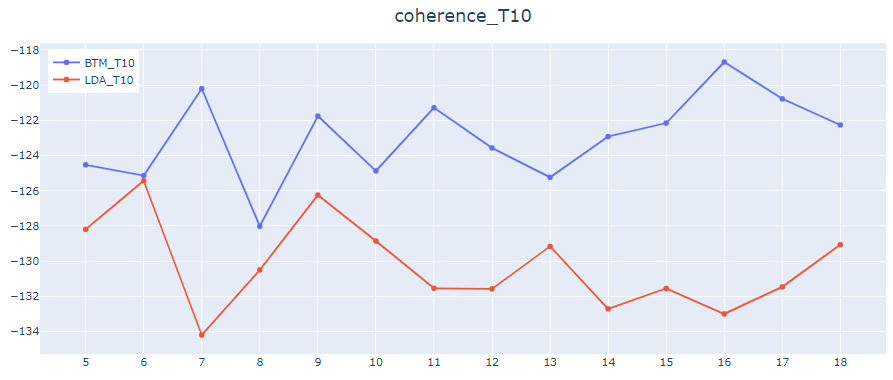
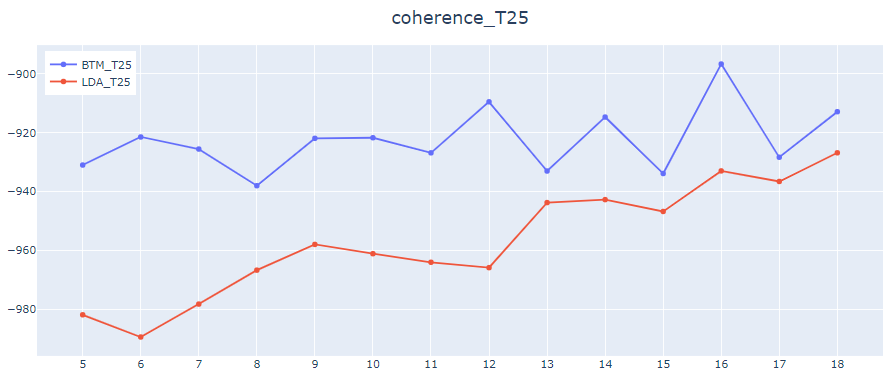
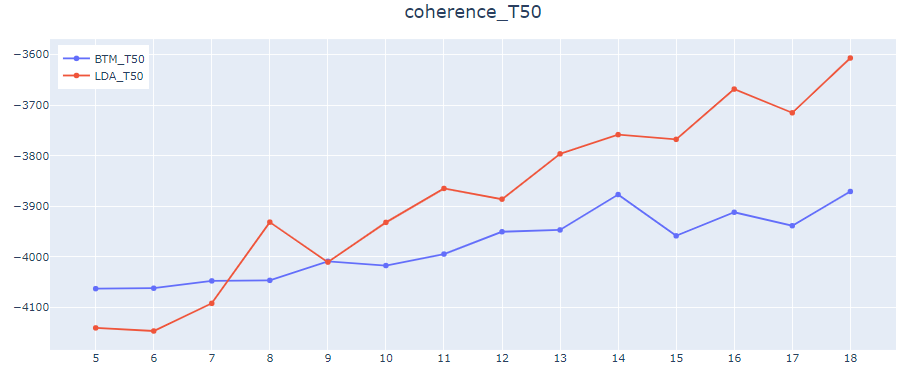
横軸がトピック数、縦軸がcoherenceの値になります。
代表単語数10or25の時は全てのトピック数でBTMの方が数値が良いですが、代表単語数50でのcoherenceは特にトピック数が多くなるとLDAの方が数値が良いですね。
パッと見での結果も合わせトータルではBTMの方が良さそうではあるのですが、絶対的な差ではないという感じでしょうか・・・。
もっと圧倒的な差を見せつけて「すごいぜBTM!」となってくれるのを期待していたのですが、そう甘くは無かったです。
今回の結果だけ見ると、スパースなデータならとにかくBTM!という感じではなく、データがスパースであっても、あくまでモデル選択の候補の一つとして捉えておくぐらいが良さそうです。
ということで、BitermTopicModelによるSNS文章解析でした。
いかがでしたでしょうか?
LDAとの比較で圧倒的な差は見せられませんでしたが、特にパッと見のトピックの分かれ方はLDAよりも良さそうな部分もあったため、先述したようにモデル候補としては十分考えられるというのが個人的な印象です。
勿論データ次第で結果は大きく変わってくると思うのですが、もっとスパースなデータで試してみればより顕著な差が見られるかもしれませんね。
また、文章データ以外でも例えば顧客毎の購買データに対してトピックモデルを適用しようとした場合、データが少ない最初のうちはどうしてもデータがスパースになりがちです。
売上を増やすためのデータ解析をしたいのに、解析をするのに十分な量の販売データが無い等、実際のビジネス現場で起こりそうな問題に対してもBTMの活用が見込めそうです。
スパースなデータを見た時には反射的にBTMをモデリング候補として挙げられるよう覚えておきたい所ですね。
ではでは!
参考
[1] Xiaohui Yan, Jiafeng Guo, Yanyan Lan, Xueqi Cheng. "A Biterm Topic Model for Short Texts". Institute of Computing Technology. 2013





