

こんにちは!sodaの古橋です。
サッカーワールドカップ、日本代表が凄い盛り上がりでしたね!
私自身はサッカーあまり詳しくないので、Twitterで細々とW杯関連のタイムラインを見て盛り上がりを感じていた程度なのですが、〇ドイツ→×コスタリカ→〇スペインの流れは素人ながらに非常に興奮しましたし、クロアチア戦もまさに死闘という感じで熱かったですね。
惜しくもベスト8はならずという結果でしたが、本当に日本代表の皆さんにはお疲れ様でした、白熱した試合をありがとうという気持ちで一杯です。
さて、ちゃっかりTwitterの話題にも触れましたが、今回はSNSでの発信内容のような比較的短い文章を良い感じに解析する手法をご紹介しようと思います。
BitermTopicModel(バイタームトピックモデル)と言い、前回ブログで取り上げたSLDAと同じくトピックモデルの一種です。
今回もまず手法をざっくり紹介し、次回ブログで実践編という流れで行こうと思います!
トピックモデルは、単語の共起性を元に文章に存在する潜在的なトピックを推定するモデルでした。
もう少し噛み砕いて書くと
・文章にはそれぞれその文章が何について触れているかというトピックが存在しているだろう
・各トピックには「存在しやすい単語」「存在しにくい単語」があり、文章(単語群)はその文章のトピックから確率的に生み出される単語の集合体とみなせるだろう
というものです。
・・後半あまり噛み砕けてない気がするのでもう少し補足を。
文章の生成をダーツで例えると、まずダーツのボードを好きな数用意し、各ダーツボードには元の文書データに存在する全ての単語を並べます。そして、各文章に存在する単語数分だけダーツを投げ(どのダーツボードに投げるかは好きに決めます)、刺さった単語を生成する、これだけです。
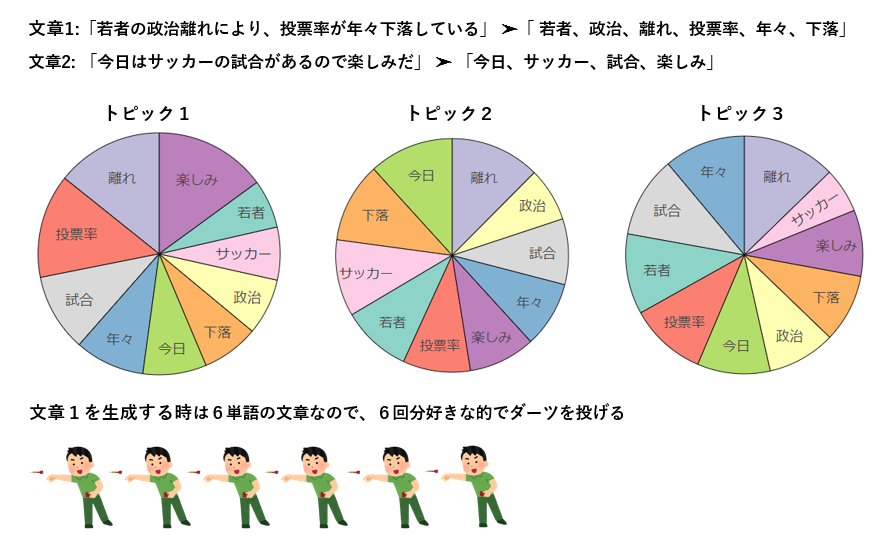
しかし当然、適当に作ったダーツボードを適当に選んで投げるだけでは元の文章とかけ離れたハチャメチャな文章しか生成出来ないので、ちゃんと元の文章に沿った生成が出来るように少し調整を加えてあげます。
調整のメインになるのが、「各ダーツボードのそれぞれの単語の枠の大きさ」と「どのダーツボードで投げるかを決める確率」で、これを良い感じにするのがモデルの学習です。
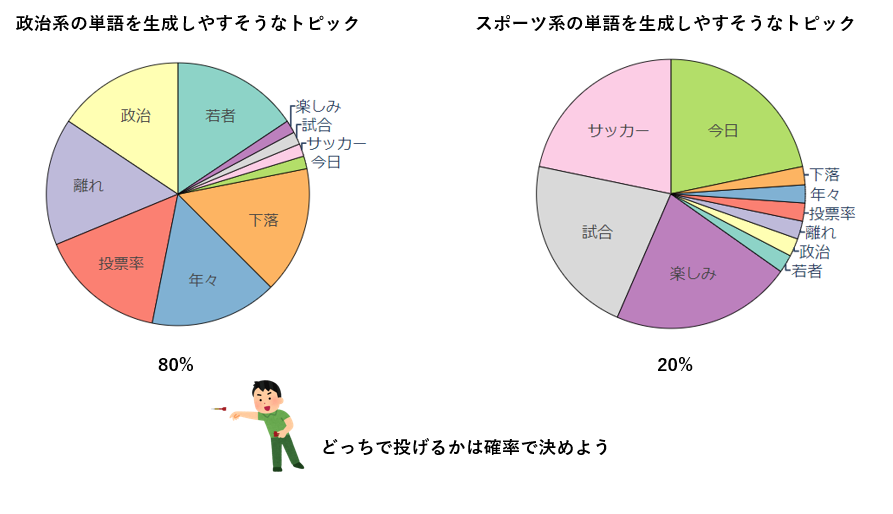
どのダーツボードで投げるかの確率は1つの文章毎に定められています。つまり、同じ文章内に出現する単語であれば同じ確率でダーツボードが選択されます。
となると、それらの単語は選ばれやすいダーツボード内で大きめの枠で配置しておいた方が刺さる確率が高そうですよね?
これにより、共起性の高い単語同士が各トピック内にどんどん集約されていき、完成したトピック分布(ダーツボードの選択確率)、単語分布(ダーツボード内の各単語の枠のサイズ)という人の目には見えない文章の隠れた意味を解析してやろうという寸法ですね。
(解析アウトプットのイメージが湧かない方は前々回の記事をご覧ください)
さて、このトピックモデル、そのままでも十分強力なのですが、さらに色んなタスクに適応出来るように改造された派生モデルが沢山あります。
前回紹介した数値付きデータに応用出来るSLDAの他にも、時系列データに対応出来るものであったり、階層的にトピックを抽出出来るものがあったり、最近では自然言語処理界に一大ムーブメントを引き起こしたBERTとトピックモデルを組み合わせたBERTopicなるものも登場しています。
では、そんな中でBitermTopicModel(BTM)は一体何を目的にして派生したモデルなのかという所で、冒頭でも挙げた、短文の文書群を良い感じに分析したいという目的を果たすために作られたモデルということになります。
・・別に文章が短くても普通のモデルで解析しちゃえばいいじゃん?
と思われる方も居るかもしれません。
確かに文章が短かろうが一般的なモデル(LDA等)で解析は行えますし、BTMも短い文章に適したモデルというだけで、特段何か新しいタスクが遂行出来るわけではありません。
小洒落た名前の割にちょっとモデルとしての魅力が心許ない気もしてきます。
ただ裏を返せば、普通のモデルは短い文章の解析には適していないということです。
一体なぜなのかという部分をもう少し掘り下げてみたいと思います。
結論から述べますと、短い文章においては特に単語のスパース性がネックになります。
スパースとは、データ中に0ばかりが並ぶということです。
そもそもトピックモデルは単語の出現分布をモデル化するものであると述べました。
この「単語の出現分布」は対象とする文章群に出現する全ての単語を候補として捉えます。
取ってくる文章の数にもよりますが、仮に1000個の文章を解析しようと思うと、1つの文章に1種類ユニークな単語が含まれるだけで単語候補数は1000を超えます。
この1000分割以上にされたダーツの的に対して、当たり(実際に文章中に登場する単語)の数が少なすぎるというのが、スパースであるということです。
ここから特定の一つの文章を生成出来るようにするだけなら別に話は難しくありません。
ダーツの的を一つ、その文章中に出現する単語のみ枠を最大限大きくし、ひたすらそのダーツボードで投げ続ければ単語の重複は出るかもしれませんが、ある程度その文章が生成されます。
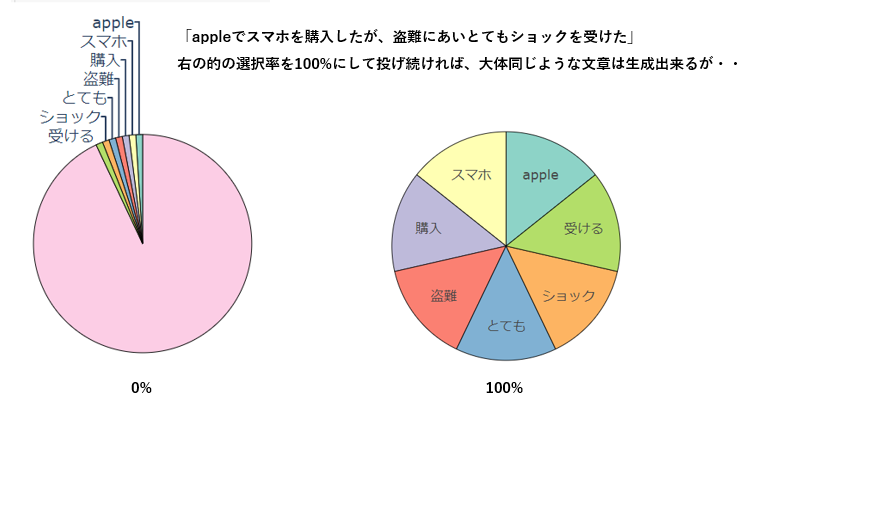
しかし、やりたいのは多くの文章に対して共通するトピックを推定することなので、一つの文章に特化したダーツボードを作っても何も意味がありません。
色んな文章に出現する単語の兼ね合いを見つつ、ダーツボードの選び方と枠の大きさをバランス良く調整してあげる必要があります。
1つの文章に登場する単語数が多ければ、枠の調整候補も多くなり、他の文章との兼ね合いも鑑みての調整がしやすそうです。
逆に登場する単語数が少ない時、極端な例としてどの文章にも2単語しか出現しないという状況だとどうでしょう?
調整幅が少ないと、当たりが少ないのでいつまでたっても当たりに刺さらないですし、思い切ってその2単語の枠をえいやと大きくすると、先ほどの特定の文章に特化したトピックを作るというのと似た行為になってしまい、他の文章で全然いい感じに刺さってくれないということになりそうです。
これが通常のモデルで短い文章を解析した時に起こるスパース性の問題のイメージになります。
Twitterのデータなんかを対象にすると、殆どの文章が10単語にも満たないデータになってしまうかもしれませんので、如何にもこの状況にあてはまりそうで怖いですね。
では、上記問題を克服するためにBTMが取っているアプローチを簡単にご説明します。
先ほどの例では、文章毎にどの的に投げるかの確率を決めてましたが、BTMではその確率が全文章で共通です。
・・へっ?、確率が同じなら同じような文章しか生成されなそうじゃん?
となりますよね。
そのためBTMでは、まず単一の文章を生成するという概念を無くしています。
BTMで生成しているのは、共起して登場している2単語のペアであり、全ての文章から抽出した2単語のペアを対象にそれらを生成するモデルを作成します。
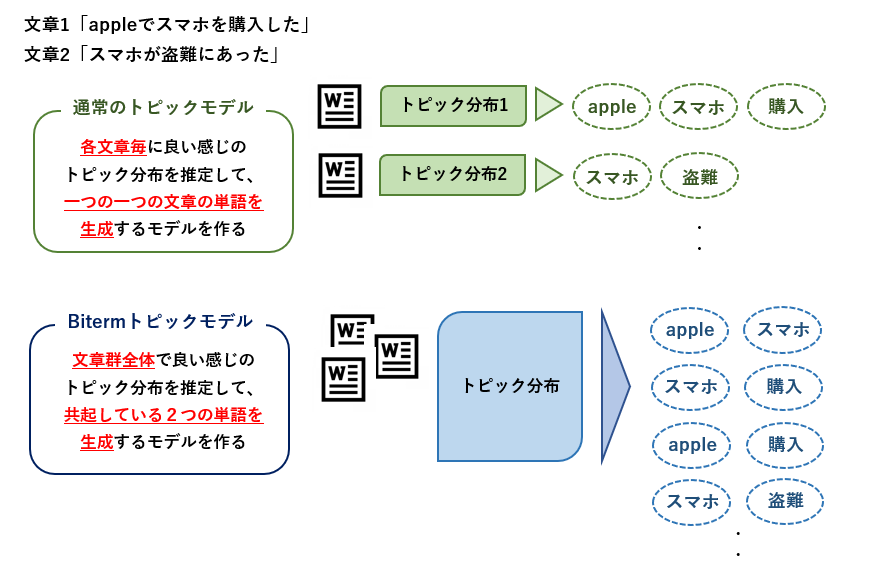
直感的には、普通のモデルでは少ない情報(文章毎の単語の共起性)から沢山のパラメータ(文章毎のトピック分布)を推定するのに対し、BTMでは沢山の情報(全文章に出現する共起単語ペア)から限られたパラメータ(文章全体のトピック分布)を推定するようにすることで学習を安定させています。
文章自体を生成するモデルじゃないのに文章の意味解析に使えるのか??と疑問に思うかもしれませんが、直接的にその部分がモデルに組み込まれていない代わりに、BTMの場合はモデル学習後のパラメータから文書毎のトピック分布を算出するための計算を用意しています。
これにより、普通のトピックモデルと同じアウトプットを保ちつつ、短い文章群に対しても安定したパラメータ推定を行うことが期待出来るモデルとなっています!
ここまで説明してきた通り、BTMはデータがスパースになってしまう短い文章での解析精度を上げる目的で考えられたモデルです。
SNSやニュース記事のタイトルのような短文の文書解析の他、文章以外でも共起性の少ない購買データの解析等にも使えそうです。
特定のタスクを追加で実行出来るようにしたモデルではなく、どれくらい文章が短ければ使うべきなどの明確な基準もないため、なかなか使い所を見極めるのが難しいかもしれませんが、短めの文章に対しては取り敢えず普通のモデルとBTM両方を試してみて、より良い方のモデルを選択するという選択肢の増加に繋がりそうです!
前回に続いてトピックモデルの派生モデル、BitermTopicModelの紹介でした。
いかがでしたでしょうか!
SNSの登場以降、文書にせよ動画にせよとにかく「早く・短く」が潮流となっている昨今なので、短文の解析に主眼を置いたBTMのような手法のニーズは今後も高まっていく期待が持てそうですね。
次回はこのBTMを使って実際にTwitterのデータを使った解析にチャレンジしてみようと思います。
ではでは!





