

どうも、sodaエンジニアの國田です。
いきなりですが、まずはこちらをご覧ください。


この画像、当然AIによるものですが、どうやって作ったと思います?
ぱっと見、写真→イラストの変換モデルに見えますよね?
ただ、この猫のイラストを生成するのに、実はイラスト画像は一切使ってません。
学習時、モデルに与えたのは文字だけ。
なんと、テキストのみで生成した画像なのです。
「そんなこと、できるわけない」って思いますよね。
それができてしまうのです。そう、おなじみのCLIPを使えばね。
ということで、今回は"StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators"(Rinon et al., 2021)[1]を紹介するとともに、テキストによる生成モデル作成の実験を行なっていきたいと思います。
CLIPを利用したモデル改変
CLIP: Contrastive-Language-Image-Pretraining models. 約4億対の画像とそれを表現するテキストを学習させたとんでもない化け物モデルです。
CLIPは画像に対し、テキストがどの程度合っているかを数値で表現することができます。
例えば、「アニメのキャラクター」というテキストにドラゴンボールの孫悟空の画像だったり、ドラえもんの画像だったりを渡すと高い数値が返ってきますし、「愛くるしい子猫」というテキストにアーノルド・シュワルツェネッガーの写真やロニー・コールマンの写真を渡すと非常に低い数値が返ってきます。この数字のことを類似度と言います。
過去、CLIPの類似度を利用することで、画像の改変をした例(GANを利用した画像編集やAIアート)を紹介しました。それらはGANの生成器が作れる画像の中からテキストに類似した画像を探してくるというアプローチでしたが、今回も同じような形で「写真→イラストの改変」ができるのでしょうか?
答えは「No」です。なぜなら「猫の写真画像」を学習したGANの生成器の中には決して「猫のイラスト画像」は含まれていないからです。
では、どうすれば、イラスト画像を生成できるようになるのでしょう?
答えは簡単。GANの生成器のパラメータを直接弄って、イラストを出すように改造してしまえば良いのです。
以下の図を用いて説明します。
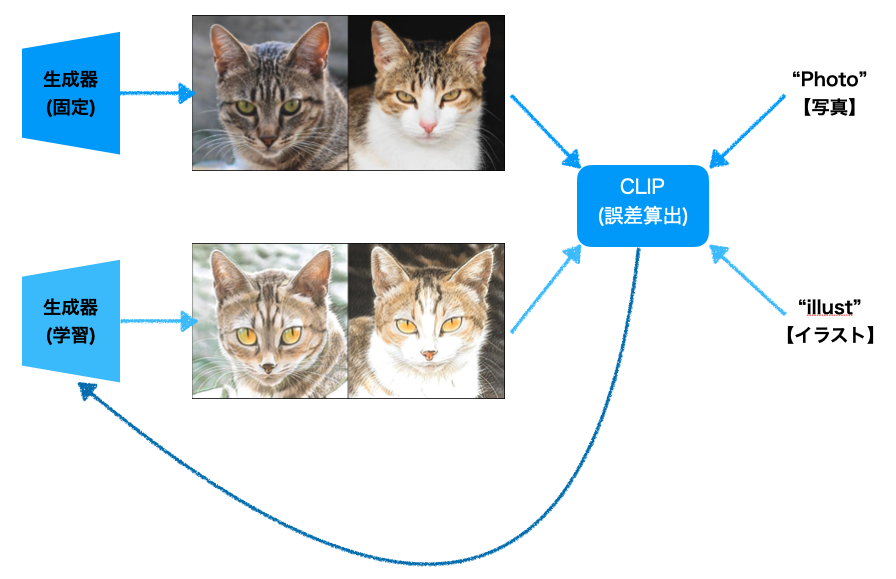
図では生成器が2つ存在していますね。生成器(固定)と生成器(学習)がありますが、どちらもGANの学習済みの生成器です。学習のスタート時点では、両者は全く同じもの(上の図の例ですと、どちらも猫の写真を生成するモデル)を用意しておきます。
学習の流れは以下のようになります。
生成器(固定)および生成器(学習)はひたすら画像を作り、生成器(学習)のパラメータを更新し続けます。
その際、更新されるパラメータは必ず以下の規則に則るように制限を与えます。
- A) 生成器(学習)と「illust」というテキストの類似度を高く
- B)【「Photo」と「illust」というテキストの差分】と
- 【生成器(固定)と生成器(学習)で生成した画像の差分】の類似度を高く
- C) 生成器(固定)と生成器(学習)で生成した画像同士の類似度を高く
A)より、まず生成器(学習)で生成される画像をひたすら「illust」に近づけていきます。
これによって、猫の写真がだんだん猫のイラストに変わっていきます。
B)が少し難しいのですが、まず、「写真」という単語と「イラスト」という単語同士を比較して、どれだけ違いがあるのかを数値化します。これと同じ違いが生成器(固定)で生成した写真画像と生成器(学習)で生成したイラスト画像の間にもある筈ですので、それを反映させてあげます。
最後に、C)により、画像の被写体に大きな違いが出ないように(≒上の例ですと、猫の種類や顔の向き、表情などはそのまま)になるように矯正してあげます。
以上を繰り返すことにより、生成器(学習)のパラメータは写真用のパラメータからイラスト用のパラメータに更新され、最終的にイラスト画像を生成するモデルが得られます。
それでは、実際にモデルを作る実験を行なっていきましょう。
画風の異なるモデル生成
まずは、犬の画像を生成する学習済みモデルを使ってみます。
「Photo」(写真)というテキストを「Watercolor Art」(水彩画)、「Painting of Ukiyo-e style」(浮世絵)、「Pixel Art」(ドット絵)、painting of Edvard Munch style」(エドヴァンド・ムンクの絵)に変えて生成させた結果が下記になります。
| 元のモデルの生成画像 |  |
| 「Photo」(写真)→「Watercolor Art」(水彩画) |  |
| 「Photo」(写真)→「Painting of ukiyo-e style」(浮世絵) |  |
| 「Photo」(写真)→「Pixel Art」(ドット絵) | |
| 「Photo」(写真)→「painting of Edvard Munch style」(エドヴァンド・ムンクの絵) |  |
テキストだけで作ったとは思えないほどハイクオリティな画像が得られましたね。
もう一度強調させていただきますが、この方法、新しい生成モデルを作っております。
直接画像を弄っているわけではないため、「Aの画像をBに変換」ではなく「Bの画像の直接生成」ができます。
つまり、新しくできたモデルを使い、以下のように大量の画像の生成が可能です。

風景の加工
できることは、画風が違うモデルの生成に留まりません。画像の色や風景さえも加工できます。
次の、車画像の生成モデルを使ってお見せしましょう。
| 元のモデルの生成画像 |  |
| 「Daytime」(昼間)→「night」(夜) |  |
| 「Car」(車)→「Car in the amazon」(アマゾンを走る車) |  |
| 「Car」(車)→「Burning Car」(燃えている車) |  |
このように、昼→夜や街中→アマゾンの情景の変化、更には炎の追加までも可能です。
夜の車はともかくとして、アマゾンを走る車や燃えている車の画像なんて集めるのは実に大変ですから、(需要があるかどうかは別にして)テキストだけでここまでの生成モデルを作れるようになるのは非常に魅力的なのではないでしょうか?
物体の加工
では、同じ方法で画像の被写体を変えることってできるのでしょうか?
冒頭にも登場した猫画像を生成するモデルを、別の動物に変更してみましょう。
| 元のモデルの生成画像 | |
| 「Cat」(猫)→「Raccoon」(アライグマ) |  |
| 「Cat」(猫)→「Wild Boar」(イノシシ) |  |
| 「Cat」(猫)→「Rabbit」(ウサギ) |  |
よくできていますね!
驚くべきことに、生成器(固定)で生成していたジャンルの画像の枠組みを飛び越え、全く新しいジャンルの画像を生成するモデルが得ることができてしまいます。
再び犬のモデルに戻りますが、以下のような形で絶対に存在しない画像を生成するモデルへと改造することも自由自在です。
| 元のモデルの生成画像 | |
| 「Dog」(犬)→「Plastic toy Dog」(プラスチック玩具の犬) |  |
| 「Dog」(犬)→「Body Builder Dog」(ボディビルダー犬) |  |
| 「Dog」(犬)→「Ghost」(幽霊) |  |
ここまで何でも生成できるのは、やはりCLIPの恩恵が大きいです。CLIPがテキストと画像の関係性を認識しているからこそ、生成器(学習)のパラメータを適切に導くことができているのです。
逆に言えば、CLIPに無いテキストを入力しても学習が進まないという問題もあります。最近生まれた造語などでは厳しいでしょうね。
いかがでしたでしょうか?
CLIPが登場したことにより、テキスト×画像のマルチモーダル分野の研究は爆発的に進んでおります。今回紹介した論文のモデルはこれまで学習に時間がかかるとされていたGANの学習時間を既存の学習済みモデルから移行学習させることで、数分単位にまで縮めているという恐ろしい成果を上げています。
GANを使った技術のビジネス応用例はまだまだ数える程度しかありませんが、ここまで簡単に高精度なモデルを作れるようになってくると、今後どんどん増えてくることでしょう。
既に「ビジネスでAIを使わない選択肢は無い」とまで言われる時代ですが、「ビジネスでGANを使わない選択肢は無い」なんて言われる日もそう遠くはないのかな、と個人的には思います。
おまけ
CLIPは人の顔画像についても非常に長けています。
これを利用すると、以下のようなものもわずか数分で作れちゃいます!

こんな画像、身の回りには絶対に存在しません。普通に学習用データを集めて、このような生成器を作ろうなんて思ったら、メチャクチャ大変そうですよね。
やはりCLIP恐るべし・・!
ではまた!





