

こんにちは!sodaの古橋です。
SLDAを用いたレビュー解析、3本目の記事になります。
今回は番外編として、モデルが学習されていく様子の可視化をしてみたいと思います。
前回まででSLDAでどんな事が出来るのかはなんとなくイメージ出来たかなと思うのですが、結果の部分がイマイチ釈然としない、「そもそもなんでこんな数値出してるんだっけ?」となる可能性も高いかなと思いましたので、今回の番外編もとい総集編で全体の流れを整理しつつ、モデル完成までの学習の流れをもう少し詳しくお見せしていきます!
データは勿論前回と同じ鬼滅の刃のレビューです。
今回も煉獄さんは不在になります。
まずSLDAとは一体何者かという所を改めて振り返ります。
最初の記事で述べたようにSLDAは、文書等の共起性のある観測データと、それに紐づく何等かの数値の生成過程をモデル化したものです。
実践編の記事ではそれに当てはまるデータとして、鬼滅の刃の映画レビューデータを解析しました。
モデル化というと何か格好よく感じますが、現実で起きた事象に対して説明性や再現性、新規データに対する予測を得るための立式を行っているという点では普通の回帰分析とかと一緒です。
違いと言えば、観測されているのが回帰分析で言う目的変数にあたる部分だけで、そこから説明変数的な部分(パラメータ)を推測するというややトリッキーな仕組みとなっている点です。
このあたりはあまり馴染みがなくて若干難しく感じるかもしれませんが、ひとまず先に進めます。
ここで、SLDAの生成過程をグラフィカルに表現したものを見てみましょう。
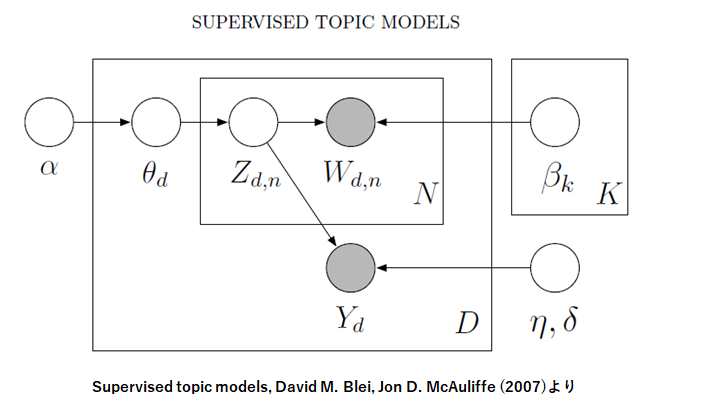
観測値である黒丸($W:text、Y:score$)に対して、色んな白丸から矢印が伸びてきています。
この白丸がまさしく、黒丸を生成するためにSLDAで仮定されているパラメータ(と潜在変数)で、全て非観測、未知のパラメータです。
なぜこんな風に未知のパラメータを仮定する必要がるのでしょうか?
このパラメータの数値を解くことで、表面上ではわからない観測データの裏にある(と仮定される)データ同士の関係性を表現したり、新たなデータの解釈を可能にするためです。
SLDAの場合は、テキストレビューと数値レビューの関係性を、潜在トピックという単語の共起性で区切ったグループによって説明するために、そういうことが出来るようにパラメータが設置してあるモデルになります。
ちなみにモデル化の目的の部分で予測と記載しましたが、SLDAでは新しい文章データが得られた時に、その文章の潜在トピック分布や、Yの値(score)を予測することが出来ます。
ちらっと前回作成したモデルに私の映画レビューを放り込んで予測を試してみましょう。
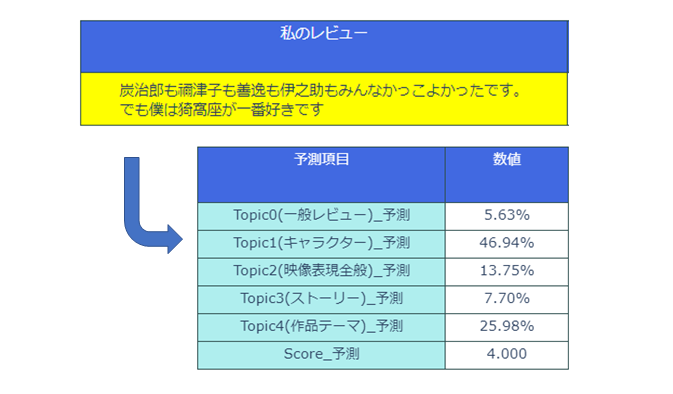
小学生並のレビューで恐縮ですが、各潜在トピックへの所属率とScore予測を得る事が出来ました。
ちゃんとキャラクターのトピック(トピック1)に高い所属率で振られていますね。
Scoreは☆4と予測されているので、今後誰かに映画の感想を聞かれたら「まぁ☆4ぐらいかな」と答えることにしときます。
さて、次にやりたいのは白丸のパラメータの値をどんな数値にすればよいかの推測です。
手法にもよりますが、今回やろうとしている推測手法では文書内の全ての単語一つ一つに割り当てる追加のパラメータのようなものもあり、それも合わせると鬼滅レビューデータでの学習パラメータの総数は約36000個というとんでもない数になります。
この大量のパラメータ達を、データにフィットするよう良い感じに学習させなければいけません・・
SLDAでは観測データという結果が分かっていてその原因となるパラメータを推定したい、こちらの記事でも紹介したベイズ推定というアプローチでパラメータの事後分布を推定します。
推定には複数のアプローチがあるのですが、今回はそのうちの一つ「変分ベイズ法」を使用します。
変分ベイズ法についてはエッセンス的な部分だけざっくり説明すると「計算出来ない事後分布の代わりに計算しやすい確率分布を置いてしまおう」っというもので、この計算しやすい分布を求めたい事後分布に近似出来れば、それが答えで良いよね?というアプローチで近似解を求める手法です。
(先ほどから出ている追加のパラメータは、この代わりの確率分布の中で登場するものです)
・・そもそも計算出来ないと言っているものに対して近似させるも糞もないだろうと突っ込みたくなるかもしれませんが、ここは深く突っ込まずに大量のパラメータを上手い事学習させられる手段があるんだなとだけ思っておくことにしましょう。
では、実際に実装して学習させてみます。
今回は元の論文に沿って変分ベイズで実装していますが、前回の実践編は別の手法でのパラメータ推定を行っていたため、出てくる答えが前回のものと結構違う可能性もあります。
どちらも厳密解を得られる手法ではないので、どちらかが正しいというわけではなく推定手法による違いと思って頂ければと思います。
まずは初期状態です。全パラメータをランダムな数値で初期化しています。

かなりレアな単語も平等に出現しているので、余計な単語(「っぱなし」「うい」など)が削除し切れていない、私の詰めの甘さが露呈しています。
ちなみに前回から上記のような形で結果をお見せしていますが、これは学習パラメータのうち$β_{k}$、$η$をまとめて表示した結果になります。
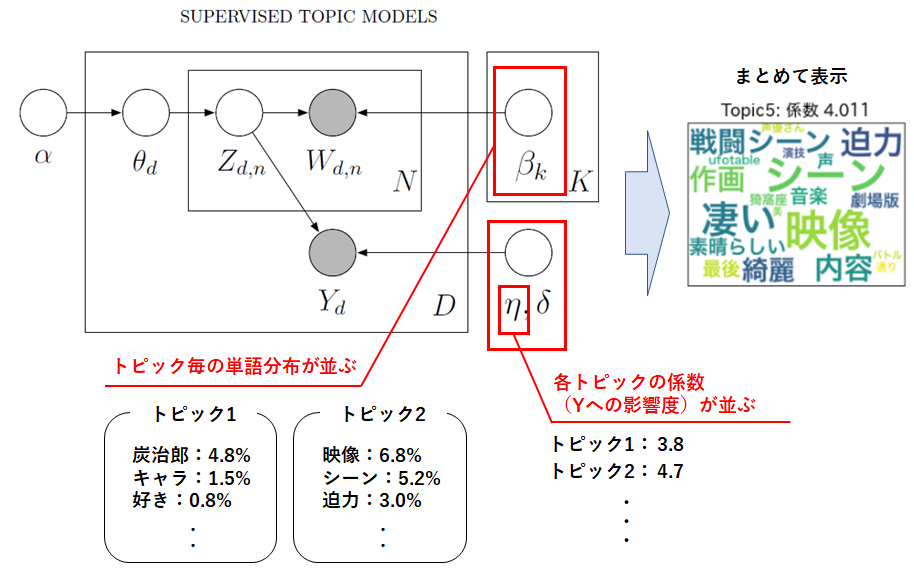
次に1回だけ学習させた状態です。

ガラッと内容変わりましたが、よく見ると殆ど同じような内容のトピックに分かれています。
まずは全体的に出現率が高そうな単語だけで埋め尽くされていますね。
では、ちょっと進めて10回学習させてみた状態です。

トピック3が映像に関するトピックでしょうか?
ちょっとずつトピック毎の特色が出てきた気がしますが、まだまだパキッとしないですね。
ここで一気に100回まで行ってみましょう。

単語も係数も、トピック毎にかなり特徴が出てきました!
トピック2なんかは大分顕著にキャラクターのトピックとして分かれていますね。
では、最終的な学習結果です。
今回は累計500回学習を行いました。

トピックの内容は凡そ前回のものと似たような別れ方になったので、前回付けた各トピックのタイトルを貼り付けておきました。
係数は各トピック毎の差が激しくなり、特にトピック0が大幅なマイナスなのが気になるところですが・・映像関連や作品テーマのトピックが高く、ストーリー関連のトピックが低いという傾向自体は前回と同じものを得る事が出来ました!
SLDAのモデルを前より少し詳しく説明し、学習の様子を可視化しました。
モデル化のためにパラメータを設置し、学習させていく流れのイメージは膨らみましたでしょうか?
学習がどうとか特に興味ないぜ!と思いつつもここまで読んでくれた方が居ましたら、数値付きのフリーアンサー等の解析に使えるモデルとしてSLDAというものがあったなということだけでも覚えておいて頂けると幸いです。
推論手法が違う上に自前で実装したものなので、前回と全然違う結果しか得られなかったらどうしよう・・と実はかなり不安でしたが、ある程度前回に近しい結果が得られてホッとしています(笑
SLDAに関する記事は、恐らく今回で終了です!
今回は小難しい話も少し挟んでしまいましたが、最後までお読み頂きありがとうございました。
ではでは!





