

初めまして!
sodaプランナーの古橋と申します。
これから業務の中で有用だったモデルや個人的に気になったものを色々発信していこうと思っていますので、見て下さった方に少しでも「面白そう!」「何か使えそう!」と思って頂けたら幸いです。
では早速、最初のお題目はSLDA(Supervised Latent Dirichlet Allocation)についてです。
・・・いきなり聞き馴染みのない単語ですが、アンケートの自由記述文等、いわゆる自然言語の解析等に使えるモデルの一種になります。
まず今回の記事ではSLDAの概略紹介を、次回記事で実際のレビュー文章データ解析にチャレンジ!という流れで進めていこうと思います。
ではでは、どうぞ。
Supervise=「監査・管理する」
「Supervised Learning」で、機械学習の文脈でいう所の「教師有り学習」になります。
つまりSLDAは、教師有りの「Latent Dirichlet Allocation(以降、LDA)」です。
これだけだとLDA??となる方も多いと思いますので、まずはこちらの説明から入ります。
さて、この記事を見て下さっている方は同じく弊社ブログ内のトピックモデルを既にご覧になられているでしょうか? (まだの方は数分で読めますので是非ご一読を!)
LDAも確率的生成モデルであるトピックモデルの一種であり、文書の潜在トピックと各トピックにおける単語の分布がDirichlet distribution(ディリクレ分布)という確率分布を元に生成されているという仮定を置いたモデルになります。
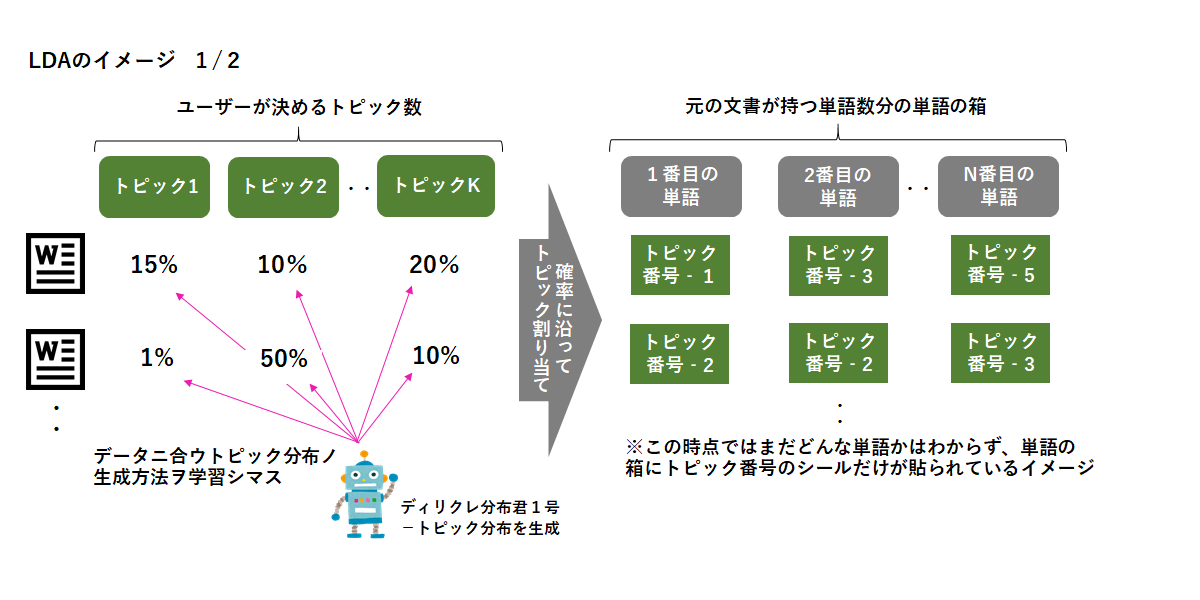
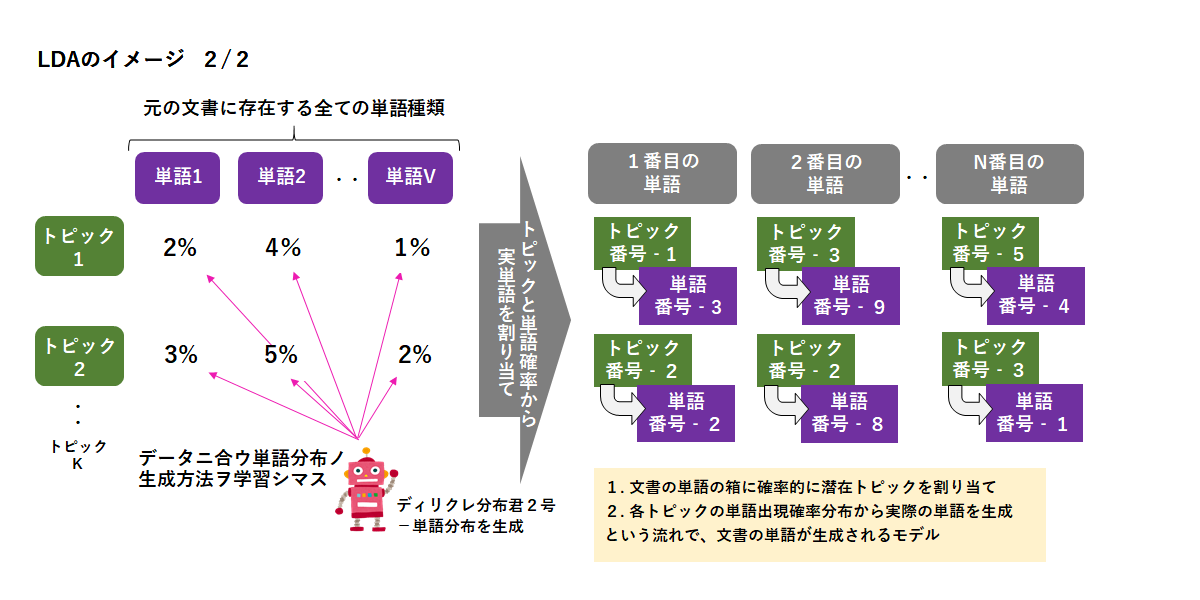
上記イラストのディリクレ分布君1号、2号が実際の文書データに合う形で確率分布の生成の仕方を頑張って学習していってくれることで、文書生成モデルが出来上がるというイメージになります。
では、LDAのイメージがざっくり把握出来たところで、本題のSLDAとは何かという話に移ります。
前述の通りLDAは文書データのモデル化のみを行うものでした。
SLDAは「Supervised」の名が付く通り、文書データと紐づく別の教師データがある時に力を発揮するモデルです。
Amazonなどの商品レビューデータ(自由記述の文章データと、☆の数という教師データ)がイメージしやすい例となりますが、そのようなデータに対して
① 文書の生成モデル(上記LDAと同じ)
② ①で割り当てられるトピックをパラメータに使用した教師データの分布モデル
①②の双方を同時に満足させるように学習を進めるモデルになります。
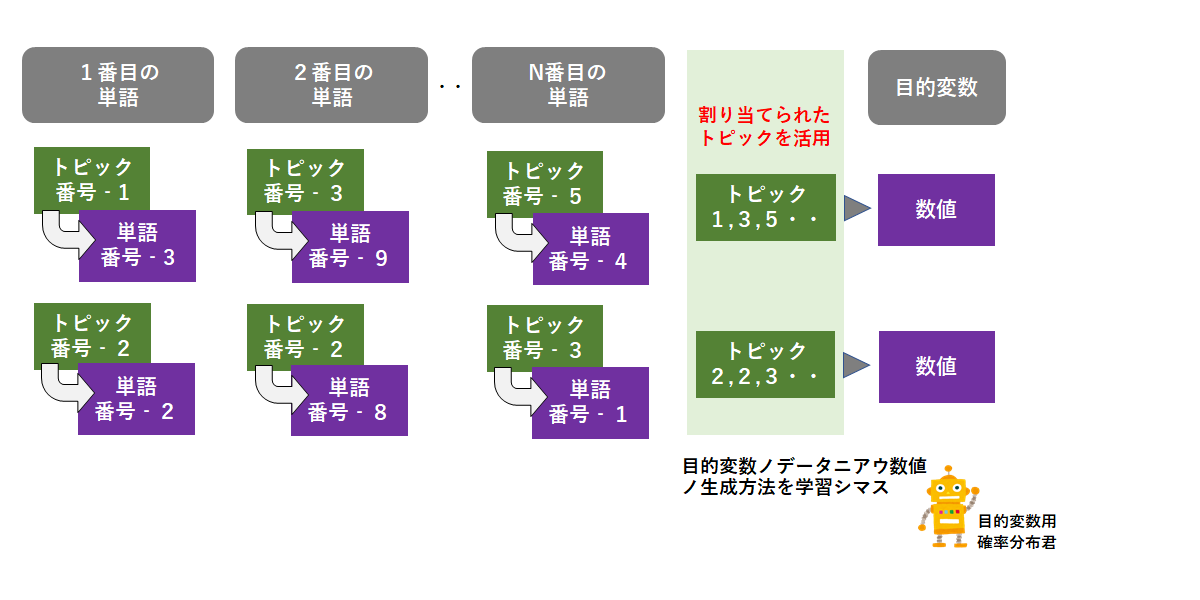
教師データの分布モデルの部分がイメージしにくい場合は、教師データを目的変数、割り当てられたトピックを説明変数とした回帰分析(予測)を行っていると思って頂ければ大丈夫です。
2つのタスクを同時に実行出来るなんて、なんだかお得感のあるモデルですね。
潜在トピックを抽出するのみだったLDAから一歩進み、各潜在トピックが教師データの増減に与える影響度を明確な数値(係数)として出すことが可能になります。
つまり、LDAでは横並びだった潜在トピックが、SLDAでは目的変数への影響度という観点で比較検討出来るようになるということです!
加えて、各トピックには単語の生成確率がぶら下がっている(LDA図解イラスト参照)ので、単語単位で目的変数に対する影響を測れるようになるというのが、SLDAの大きな利点と言えます。
ユースケースとしては基本的にトピックモデルの記事内でも挙げられているように、共起性のあるデータ+教師ラベルとなる数値データが対象です。
仮に前述のAmazonレビューデータのようなECサイトのレビュー文と評価値をSLDAで解析すると、通常の潜在意味解析の結果に加えて下記のような結果が得られます。
・高評価に繋がっている潜在トピック、低評価に繋がっている潜在トピック
・同じく高評価に繋がっている単語、低評価に繋がっている単語
SLDAで解析することでその機能が好評なのか不評なのか、評価値にどれくらいの影響を与えているかを一目で判断出来るようになるということです!
他にも
SNSに投稿された文章といいね数で解析➤どんな内容の投稿がいいね数の増減に寄与しやすいか
社内での社員満足度アンケートの結果で解析➤社員がどこに、どれくらいの不満を感じているか
等、幅広いデータに対して活用が見込めます。
ざっくりでしたが、ここまでがSLDAの概略紹介になります。
概要だけ見ると単純にLDAの上位互換のようでなんだかうさんくさくも感じますが、以下のような点は気になる所です。
1. 予測の方に引っ張られてトピックの抽出が上手く行かなくなってしまうのでは?
2. そもそもトピックの数値だけでまともな予測が成り立つのか?
特に1の方が個人的に気になるところですね!
せっかく数値予測が出来るようになっても、元となる潜在意味解析の結果がぐちゃぐちゃになってしまっては元も子もありません。
このあたりを次回の実践編で考察していければと思います。
データは今や国民的アニメとなった「鬼滅の刃」の「劇場版 無限列車編」レビューデータを使用する予定です。
お楽しみに!





