

こんにちは、sodaエンジニアの國田です!
最近、GANの技術に夢中な私ですが、今回もまたGANを使って実験してみたいと思います。
題しまして、「顔面ミックス!私の顔に海外の人の顔を混ぜてみる」です。
さて、前回、「GANは私の顔を作れるのか?」というテーマで実験しました。
そこでできた私の顔画像は、GANの生成器の中にある潜在空間(顔画像の概念)から、私の顔っぽい変数を取り出して作られたものでした。
この私の顔を表す変数(以下、潜在変数と言います)が最終的な顔画像の生成までにどのように使われているのかと言いますと、以下の図のようになっています。
(図は前回の実験でも使用したStyleGAN2のアーキテクチャを説明のために簡略化したものです。詳しいネットワーク構造を知りたい方は論文(*1 *2)をご参照ください。)
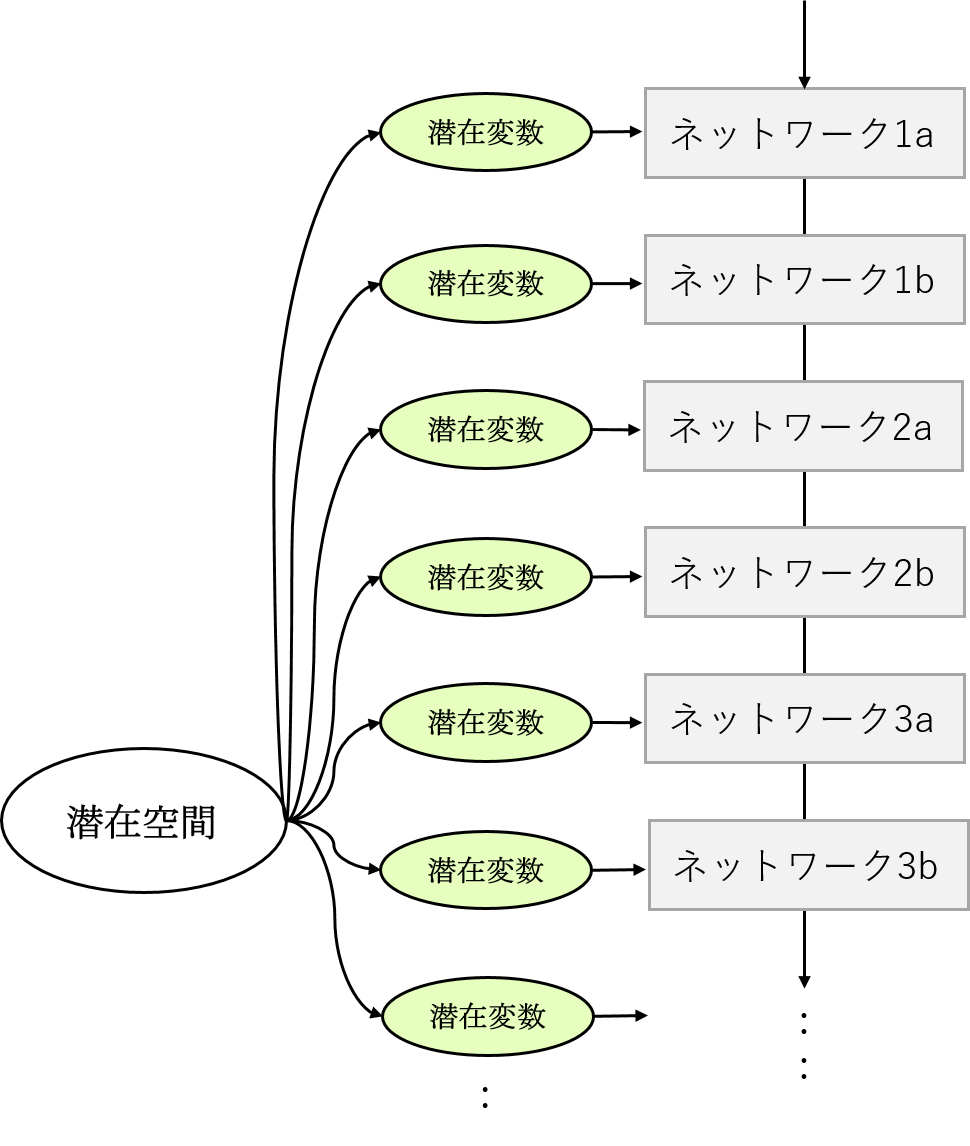
図左側の潜在空間からの矢印を見ると分かるように、何度も潜在変数を取り出して、ネットワークに渡しています。つまり潜在変数を使うのは一度きりではなく、複数回の機会が与えられているわけですね。
私の顔を生成させる場合、この潜在変数は全て私自身の顔を表す潜在変数でした。では、ここで渡す潜在変数を途中から他人の変数に変えたら、何が起こるのでしょうか?
きっと、私の顔の特徴と他の人の顔の特徴が混ざりあって新しい人の顔画像ができることでしょう!
また、この潜在変数のミックス割合をいい感じに変えることで私自身の顔の特徴を保ったまま、ちょっぴりイケメンにしたり、ゴツいクールガイの画像にしたりできるのではないでしょうか?
実験開始!
ということで、やってみましょう。
まずは、どういった割合でミックスさせれば良いかを見極めるための実験を行います。
今回使用する学習済みモデルには、潜在変数を渡す機会が全部で16回あります。最初何回かは私の潜在変数を連続で与え、途中から他の画像の潜在変数に切り替えてみました。
下の表が結果です。
表内画像の左側は私の潜在変数のみで作った私の顔画像。真ん中がミックスさせる画像、一番右側がGANでミックスした結果になります。
| 自分の顔の潜在変数を 与えた回数 |
生成画像 (左:私の顔 中:混ぜる画像 右:結果) |
|
2回 /16 |
 |
|
4回 /16 |
 |
|
6回 /16 |
 |
|
8回 /16 |
 |
|
10回 /16 |
 |
|
12回 /16 |
 |
ざっくり結果をまとめますと、
- 最初2~4回程度私の画像を通した場合、面影は殆ど残らない。
- 6~8回で、私の顔画像の面影を残したまま、イケメンになる(主観)。
- 10回以上だと、元画像と大差ない。肌の感じが多少変わる程度。
以上から、6回自分の顔の潜在変数を入力し、残りは他の画像にすると理想的な結果が得られそうです。
では、様々な画像とミックスさせていきましょう!
幸い、GANの中には様々な画像が入っておりますので、無限に生成することができます!
以下、一気に掲載させていただきます。
上段:ミックスに使った画像
下段左:私の顔画像
下段その他:私の顔画像と上段の画像のミックス結果







髪や肌の色、光の当たり方などの細かい特徴を上段の画像から引き継いでいるのがよく分かると思います。一方で顔の向きや輪郭、髪型、メガネなどのベースとなる特徴は活きたままで、どの画像とミックスさせても、ある程度本人の面影を残したままであるようにも見受けられますね。
面白いのは、女性の潜在変数を混ぜた場合でも、殆どのケースで男性の見た目でキープされる点。
輪郭(骨格)などの情報が私の顔画像のままなので、当たり前と言えば当たり前かも知れませんが、中にはヒゲが付け足されるようなパターンもあって驚きです。
ただ、どのケースで見ても髭は私自身のと似た位置に出現していることから、髭の有無を決める変数はネットワークの初期の方にあるのかも知れません。
いかがでしたでしょうか?
個人的には、かなり面白い結果が得られたかな、と思います。こうやってGANで作った画像をSNSに掲載したり、プロフィール画像にしてみるのも良さそうです。
外国人とミックスした画像を友達に見せて、「これ、僕の親戚なんだ」なんて紹介したら、信じてしまいそうなくらいの高いクオリティはあるように思えます。悪用厳禁ですかね、これ笑
ではまた!
参考
*1 Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen and Timo Aila, "Analyzing and Improving the Image Quality of StyleGAN" 2019, (https://arxiv.org/pdf/1912.04958.pdf)
*1 Tero Karras, Samuli Laine and Timo Aila, "A Style-Based Generator Architecture for Generative Adversarial Networks" 2018, (https://arxiv.org/pdf/1812.04948.pdf)





