

こんにちは!sodaエンジニアの國田です!
今回はGANの変換タスク編に関する記事になります。
そもそも、「GANって何?」って方は、こちらの記事を参照いただけますと幸いです。
GANの変換タスクとは?
GANを用いた変換タスクで有名なものとしましては、「人物写真をアニメ風に変換」、「馬の写真をシマウマに変換」とか「風景写真を油絵風に変換」などがあります。まずは、その変換のメカニズムについて簡単に解説したいと思います。
具体的に、人物写真をアニメに変換するプロセスを考えてみましょう。
GANには、「生成器(Generator)」と呼ばれるネットワークと、それに敵対する「識別器(Discriminator)」がありましたよね?この場合、生成器は、人物写真をアニメに変換する仕事を請け負い、識別器は、アニメ画像が変換された画像なのか、それとも本物のアニメ画像なのかを判断すれば良さそうです。
でも、ちょっと待ってください!
写真をアニメに変換すると言っても、変えてはいけない部分もありますよね?
肌の質感や目鼻口のサイズ等はアニメ風になってもOKですが、髪型や髪の色、装飾品や服までアニメ美少女と同じものになってしまうと困ります!極端な例えになりますが、タンクトップを着た坊主頭のマッチョな男性が、ワンピース姿で髪の長いスタイル抜群な美少女キャラクターに変換されてしまうケースも考えられます。
マッチョから美少女アニメキャラクターになるのではなく、マッチョからアニメ風マッチョになって欲しい‥つまり、写真をアニメに変換する際に、元の写真の情報をある程度保持していて欲しいわけです。ということは、変換されたアニメ画像の中に、元の写真の情報を残し、その残った情報を基に、変換前の人物写真を再生成させることができれば、パーフェクトと言えます。
そこで出てくるのが、再変換という考え方です。
つまり、人物写真→アニメの変換を施した画像をもう一度、アニメ画像→人物写真に戻す処理を入れれば良いのです!これを実装するためには、下記のように識別器と生成器をそれぞれ2つずつ用意することになります。
- 画像A → 画像Bに変換する生成器AB
- 画像A → 画像Bの変換が本物かどうかを識別する識別器AB
- 画像B → 画像Aに変換する生成器BA
- 画像B → 画像Aの変換が本物かどうかを識別する識別器BA
以上の4つの生成器と識別器を使うと、次のような流れで学習が進みます。
①識別器の訓練:真の画像、偽の画像(A⇒B⇒A'、B⇒A⇒B')を識別器AB, BAに入力し識別器を訓練します。
②生成器の訓練:生成器AB, BAに画像を入力し、識別器を騙せるような画像の生成を行います。
③上記①②を繰り返します。
さぁ、やってみよう
では、変換タスクの仕組みの解説が終わったところで、実際にやってみたいと思います。
今回、2つのテーマで、試してみました。
①【初級編】線画変換
②【中級編】アメコミ風変換
まずは、線画変換です。「写真→線画なんて、輪郭取るだけだから簡単でしょ!」と思い、トライしてみました。
学習開始直後(1,000回)は、こんな感じ。
顔写真→線画変換

もういきなり上手くいってますね笑
GPU1個で、1時間程度でできました。これで終わって良いのでは‥と思ってしまう私です。
が、そうは問屋が卸さない!上で生成された線画をもう一度顔写真に戻してみましょう!

Oh...! こちらの再現度は低いですね。全員茶髪&似たような顔立ちになっております。単純に「顔写真から線画を作るGANを開発したい」ということであれば、ここの再現度は度外視してしまっても良いのですが、せっかくの変換タスクへの挑戦!逆変換の方も何とか実現させ、線画→顔写真のGANもついでに作りたいところ・・。
ということで、もう暫く回してみることに・・!
20,000回ほど学習させてみます!

線画は、1,000回の時よりもやや濃いめに出ている印象‥!(目がちょっと怖い・・)
では、逆はどうでしょう?上の画像を線画→実写の変換を施してみると‥

うん!まぁまぁ良い感じになってますね!
もう少し続けてみます。
123,000回

そして逆変換

良いですね~!再変換の前後で髪の色の違いは出てしまいますが、元々、線画変換で相当な情報量を削ぎ落してしまっている筈!(特に色に関する情報はかなり失われている気がします。)それを踏まえると、ほぼ完璧に再現できていると言っても良いのではないでしょうか?
では、次はアメコミ風変換に挑戦してみましょう!
まずは、学習開始後5,000回目

既に良い感じですね!アメコミ変換後の画像では、額に皺のような文様が残る点や顔の輪郭がやや歪な点など、細かい部分が少し気になりますが、概ねできていると言っても良さそうです。
では、逆変換は‥

写真というより油絵っぽくなっております。
まだまだ学習が足りないようですので、もう少し進めてみます。
69,000回目


写真→アメコミ変換は、皺が消え、かなり綺麗な画像ができるようになりましたね!
一方で逆変換は、だいぶ写真っぽくなったものの、なんだかピンボケしてる感じ。
157,000回目

すごく綺麗!文句なしのアメコミ風変換です。
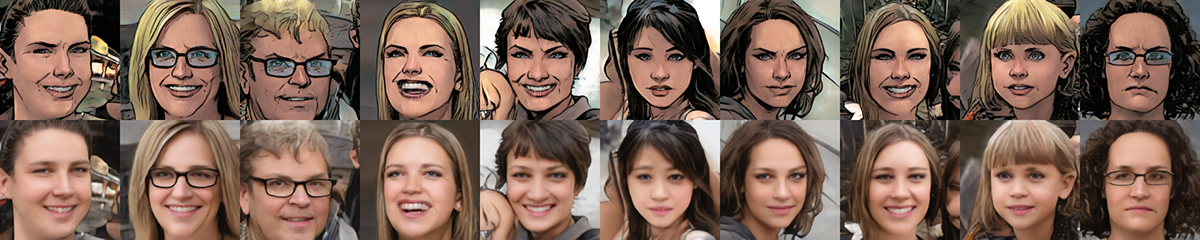
逆も綺麗にできていますね!
変換タスクは、変換前の情報が変換後にもきちんと反映されているかが肝になります。そういう意味では、今回行った2つのタスクは、変換前と変換後の間で情報の差分が比較的小さく、学習も進みやすい内容に類別されると思います。(変換前後で目鼻の大きさや顔の輪郭が変わるなどがあると、学習が非常に難しくなってきます。)
また、GANは学習させる画像もキチンと選ばなくてはいけません。学習させる画像にバラつき(例えば、顔写真の向きが全部異なる、アメコミの画風が全部異なるなど)がある場合も学習が上手く進まず、大苦戦しました。機械学習や深層学習全般にも言えることですが、入力するデータのクレンジングは本当に大事なのだと感じさせられました。
参考
Comic faces (paired, synthetic) -a paired dataset for pix2pix or similar model training
Pretty Face Images creates from StyleGAN2, faceParser and Sketch Simplification





