

トピックモデルは、自然言語処理の分野で用いられる統計的潜在意味解析の一つで「言葉の意味」を統計的に解析していく手法です。
統計的潜在意味解析では、文章を複数の単語の集まりであると捉え、それら単語の共起性に着目して文章をいくつかのクラスに分類していきます。そのクラスに集まっている単語が意味する内容を「潜在的的な意味=トピック」と考えます。トピックモデルでは、文章が複数の潜在的なトピックからなり、それらは確率的に生成されると仮定し、単語がそのトピックの確率分布に従って出現すると捉えます。
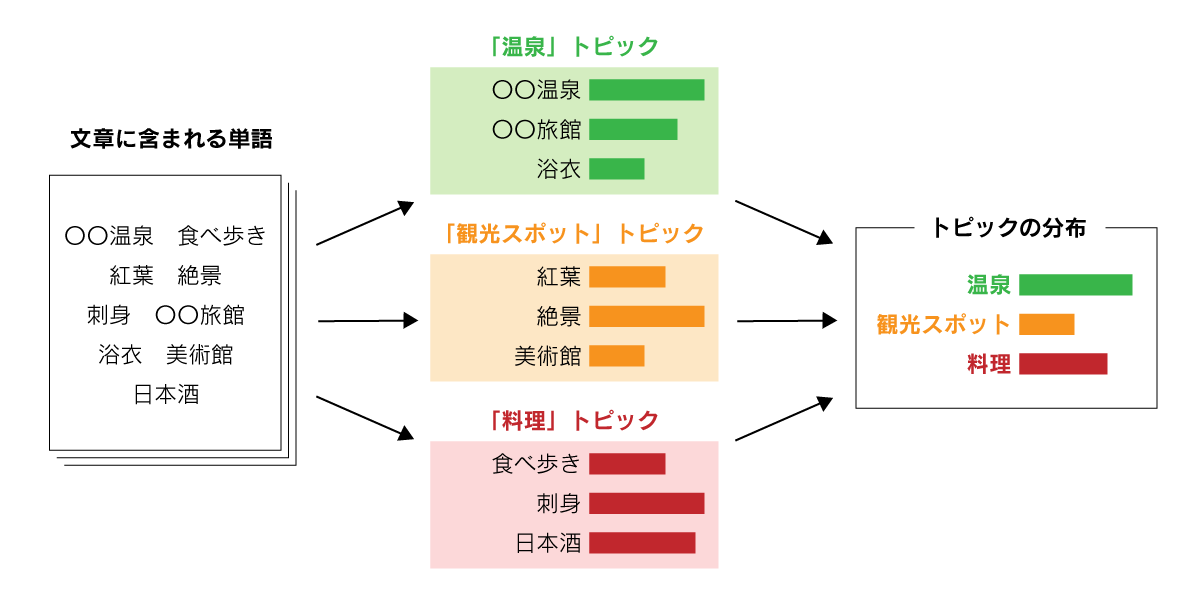
例えば「温泉旅館のレビュー」について書いてある文章があった場合、そこには「温泉」についてだけではなく、「観光スポット」や「料理」などについても書かれていることが想像できます。これをトピックモデルで解析すると、文章はそれぞれのトピックの出現しやすさ(確率分布)、また、文章中に出現する単語の特定のトピックにおける出現しやすさ(確率分布)を値として持っています。つまり文章と単語をそれぞれ共通の「トピック」で説明することが可能になります。このように得られたトピックと単語の確率分布から、トピック同士の類似度や文章の隠れた意味を解析していくことが可能です。
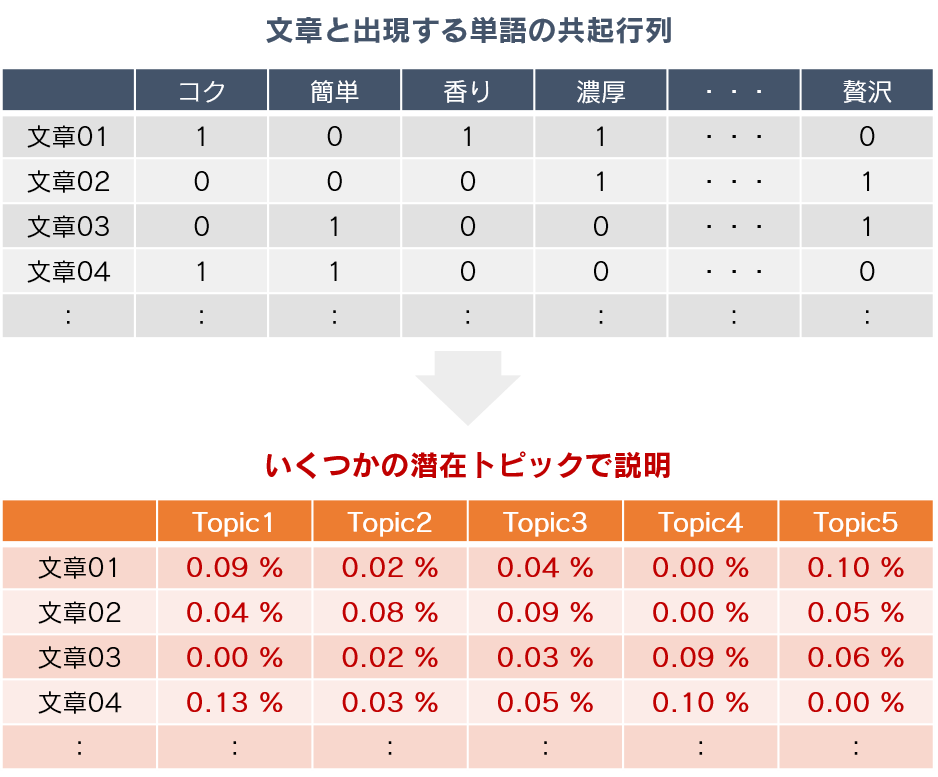
トピックモデルは記事などの探索や分類によく利用されていますが、他にもアンケートの自由記述から潜在トピックを探るような事も考えられます。また、文章以外でも共起性のあるデータであれば適用することが可能なため、例えばID-POSデータであれば会員の購買履歴を潜在トピックに分類してユーザークラスタリングやレコメンドに活用することも考えられます。
トピックモデルや自然言語処理の活用にご興味のある方、詳しい説明が必要な方はこちらからお気軽にお問合せください。





